# 为什么要有 Redis Cluster 集群?
大家好,我是小林。
今天想跟大家聊聊 Redis Cluster 集群这个话题。
说起来这也是面试里的老常客了,有位读者前两天面字节的时候就被问到了这么一道题:
Redis Cluster 集群的工作原理是什么?客户端是怎么知道该访问哪个分片的?
这个问题说小不小,说大不大,难点是里面涉及的概念挺多的,像哈希槽、MOVED 重定向、ASK 重定向、Gossip 协议、故障转移,稍微抓不住主线就会越讲越乱。
所以这篇文章,小林准备顺着一条主线把这些概念一个一个串起来讲明白。读完之后,你不仅能把这道面试题轻松答下来,更重要的是,会对 Redis 集群的核心工作原理有一个完整的认识。
我们不急着讲「Cluster 是什么」,先来想一个问题。
# 1. 为什么我们需要 Redis Cluster?
要理解一样东西「为什么要有」,最好的办法就是先看看「没有它的时候,我们遇到了什么问题」。
# 1.1 单机 Redis 能扛多久?
一开始,大家用 Redis 都是单机部署,就一台机器,跑起来就能用,简单粗暴。但这种部署方式有两个天生的坑。
第一个坑是可用性。这台机器一旦宕机,整个服务就 GG 了,所有依赖 Redis 的业务全都得跟着歇菜,体验极差。
第二个坑是容量。一台机器的内存总是有上限的,你买得起 64G、128G 甚至 512G 的服务器,但内存不可能无限堆。而且你可能还没意识到,Redis 的内存越大,持久化时 fork 子进程的耗时就越长,阻塞主线程的风险也就越高,到后面甚至会出现「内存够用但 Redis 已经带不动」的情况。
为了解决第一个坑,Redis 先后给出了两个方案:主从复制和哨兵。
主从复制让一个主节点带若干个从节点,数据从主同步到从。主挂了,从还能兜一下读请求。但这个方案有个尴尬的地方:主挂了之后,谁来把从节点切换成新的主?只能靠人肉上去搞,显然不够自动。
于是有了哨兵。哨兵的作用就是一群「看门大爷」,它们 7x24 小时盯着主节点,一旦发现主节点挂了,就自动从从节点里挑一个出来接班,全程不需要人工介入。到这一步,Redis 的高可用问题算是基本解决了。
但请注意,我们刚才解决的只是第一个坑,第二个坑还在那儿趴着呢。
# 1.2 哨兵解决不了的问题
我问大家一个问题:哨兵模式下,主节点和从节点里保存的数据是一样的还是不一样的?
答案是完全一样的。因为从节点就是主节点的复制品,主有什么它就有什么。
这就意味着,不管你挂多少个从节点,整个系统能存下的数据量还是一台机器的内存上限。比如你主节点是 64G 内存,配了 5 个从节点,总的集群内存是 64 * 6 = 384G 吗?不是的,还是 64G,其余的几台机器都是拿来做冗余备份的,存的是同一份数据。
那如果你的业务数据就是要存 200G 呢?这时候光靠哨兵就完全无能为力了。
怎么办?其实大家稍微动动脑子就能想到一个朴素的办法:既然一台机器装不下,那就把数据拆开,存到好几台机器上。比如一台存一部分,另一台存另一部分,每台机器只负责一小块,合起来才是完整的数据集。
这个思路有个专门的名字,叫「切片集群」,英文叫 sharding。它的核心思想就一句话:
把一个大数据集切成多份,分别存到多台机器上,让整个集群的容量随机器数量线性扩展。
切片集群只是一个通用概念,具体怎么实现其实有好几种方案,比如客户端自己分片、用代理(像 Codis、Twemproxy)来分片等等。而我们今天要聊的 Redis Cluster,就是 Redis 官方从 3.0 版本开始提供的切片集群方案,属于「亲儿子」级别的。
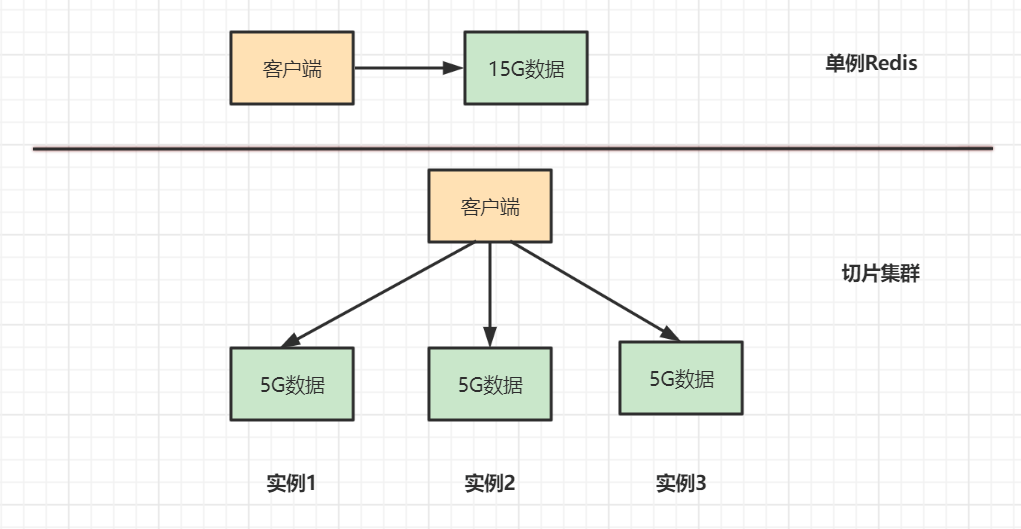
所以你看,Cluster 要解决的核心问题其实就一个:怎么把数据分散到多台 Redis 上,同时还要保证这些 Redis 合起来用起来像一台一样顺手。
顺着这个问题往下想,下一步要回答的自然就是:数据到底该怎么分呢?
# 2. 数据怎么分?哈希槽到底是个什么东西
要把数据切到多台机器上,最核心的问题就是:给你一个 key,怎么决定它该存到哪台机器上?
这个问题如果让你来设计,你会怎么做?我们一步一步来。
# 2.1 最朴素的办法:key 直接对机器数取模
最容易想到的办法是这样:假设有 3 台 Redis,对 key 算一个哈希值,然后用这个哈希值除以 3 取余,余数是 0 就放第一台,是 1 就放第二台,是 2 就放第三台。简单,公平,一看就会。
但这个方案有一个致命的问题,小林举个例子你就明白了。
假设现在集群里有 3 台机器,你有一个 key 叫 user:100,算出来 hash 是 6,6 % 3 = 0,所以这个 key 存在第一台机器上。
过了一段时间,业务数据越来越多,你又加了一台机器,现在集群里有 4 台了。客户端再来访问 user:100,这次算出来 6 % 4 = 2,跑去第三台机器找,结果发现根本没有。为啥?因为数据还在第一台呢。
这时候你就会发现,每次加机器或者减机器,几乎所有 key 的位置都要重新计算,意味着你几乎要把整个集群的数据重新搬一遍。这个成本高得离谱,业务根本受不了。
# 2.2 升级一下:引入一个「中间层」
有没有办法让扩缩容的成本小一点?
聪明的工程师想出了一个办法:不让 key 直接对应机器,而是在 key 和机器中间加一层「槽」。具体是这样的:
先预设好一个固定数量的「槽」,比如说 16384 个,这些槽的数量是写死的,永远不变。然后:
- key 不再直接映射到机器,而是先映射到某个槽;
- 机器不再直接装 key,而是「认领」一批槽,装在这批槽里的 key 就归它管。
一图胜千言,整个关系大概是这样的:
key → 哈希槽(固定 16384 个,永不变) → 机器(可增可减)
这样一来有什么好处呢?你想想看,当集群扩容增加一台机器时,我只需要从已有的机器里匀一部分槽出来给新机器就行了,槽里面装的 key 根本不用动。因为对 key 来说,它只认自己属于哪个槽,至于这个槽归哪台机器管,那是集群内部的事情,跟 key 没半点关系。
换句话说,扩缩容时迁移的粒度从「一个个 key」变成了「一批批槽」,而槽的数量是固定的、迁移起来也可控多了。
这就是 Redis Cluster 哈希槽的设计思想,说白了就是在 key 和机器之间加了一层「解耦」。
# 2.3 那 key 是怎么算出槽号的?
Redis Cluster 用的是一个叫 CRC16 的哈希算法。每个进入集群的 key,都会先用 CRC16 算出一个哈希值,然后对 16384 取模,得到的结果就是这个 key 所属的槽号,取值范围是 0 ~ 16383。
用一个公式表达就是:
slot = CRC16(key) % 16384
小林知道你现在肯定在心里嘀咕:为啥偏偏是 16384 呢?不是 65536,不是 8192,怎么就选了这么一个奇怪的数字?这里小林先卖个关子,文章最后会专门用一节来聊这个问题,现在我们先继续往下。
# 2.4 槽是怎么分给各个节点的
槽算出来了,具体哪个槽归哪台机器呢?这个是在集群初始化的时候就安排好的。Redis 会把 16384 个槽尽量平均分给每个主节点。比如说你有 3 个主节点 A、B、C,那一种常见的分配是:
- 节点 A 负责 0 ~ 5460 号槽
- 节点 B 负责 5461 ~ 10922 号槽
- 节点 C 负责 10923 ~ 16383 号槽
合起来正好把 16384 个槽全部覆盖完,一个不多一个不少。集群里每个节点都会在本地维护一份完整的「哪个槽归谁管」的映射表,节点之间也会不停地互相同步这份信息(具体怎么同步的我们后面讲 Gossip 的时候会说)。
好,现在你已经理解了数据怎么分。但是新问题又来了:
客户端发一个 SET key value 命令的时候,它怎么知道要发给哪一台 Redis 呢?总不能先挨个问一遍吧?
# 3. 客户端是怎么知道该访问哪台机器的?
这一节是整个 Redis Cluster 里最容易让初学者迷糊的地方,小林慢慢给你讲。
# 3.1 最笨的办法:每次都让服务端告诉我
我们可以先设想一个很笨的办法:客户端随便挑一台节点发请求,如果发对了那最好,如果发错了,就让服务端返回一个「你应该去找哪个节点」的提示,然后客户端再重新发一次。
这个办法能用吗?能用,但性能太差了,每次请求最坏都要走两趟,实际生产里没人会这么干。
# 3.2 真实方案:客户端自己缓存一份「槽 → 节点」的地图
Redis Cluster 真正的做法是这样的:客户端在启动的时候,会主动去任意一个节点拉一份「哪个槽归哪台节点管」的映射表,把它缓存在自己本地。
你可以把这份表想象成一张地图,上面清清楚楚写着「0 ~ 5460 号槽在 A 节点」「5461 ~ 10922 号槽在 B 节点」等等。
之后客户端每次要访问一个 key,就会先在本地做三件事:
- 用 CRC16 算出这个 key 属于哪个槽;
- 查本地地图,看看这个槽归哪个节点;
- 直接发请求给那个节点。
整个过程全是本地计算,不需要问任何人,所以一次请求就能命中,效率非常高。这种带着本地缓存地图的客户端,我们一般叫它 Smart Client(智能客户端)。Java 的 Jedis、Lettuce,Go 的 go-redis,甚至你用 redis-cli -c 加了 -c 参数后,都是 Smart Client 的行为。
# 3.3 地图过期了怎么办?MOVED 重定向出场
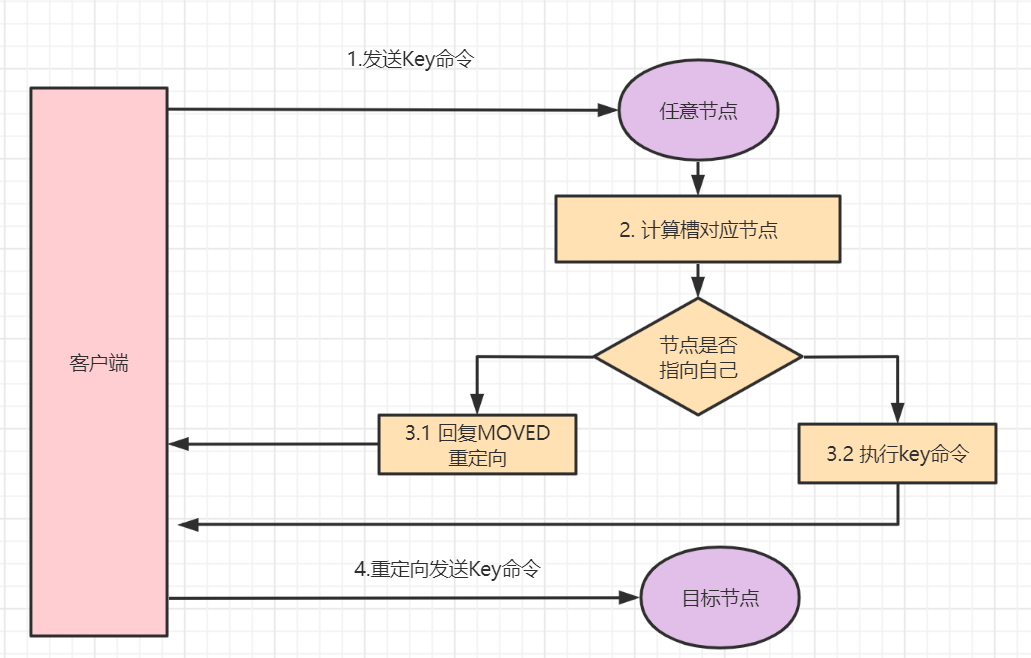
不过你肯定马上会问:这张地图是客户端启动时一次性拉下来的,万一集群后面扩容或者缩容了,槽的归属变了,客户端本地地图不就过期了吗?
这个问题 Redis Cluster 当然也考虑到了,它用的解决方案叫 MOVED 重定向。
过程是这样的:假设客户端本地地图里记的是「槽 100 在 A 节点」,但实际上因为扩容,槽 100 已经被迁到了 B 节点。客户端还是按照老地图把请求发给 A,A 一看这个槽自己早就不管了,于是不会去处理这个请求,而是返回一个 MOVED 错误,错误里带上新的地址:
(error) MOVED 100 192.168.1.2:6379
意思是:「兄弟,槽 100 已经搬到 192.168.1.2:6379 那儿去了,你去找它」。
客户端收到 MOVED 之后做两件事:
- 立刻更新本地地图,把槽 100 的归属改成 B 节点;
- 重新把请求发给 B 节点,完成这次操作。
注意第一步,这非常关键。因为更新了本地地图之后,下次再访问属于槽 100 的 key,就能一次命中了,不会再走一趟错路。所以 MOVED 错误虽然偶尔会出现,但客户端会「越跑越聪明」,不会一直走冤枉路。
流程图长这样:
# 3.4 正在搬家中的槽怎么办?ASK 重定向
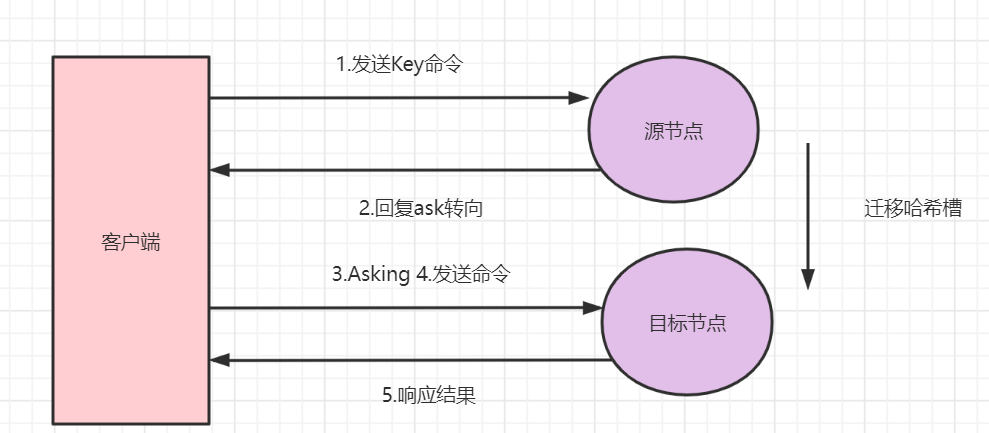
还有一种更微妙的情况:槽不是已经搬完了,而是正在搬的过程中。
想象一下这个场景:我们正在把槽 100 从节点 A 迁到节点 B,迁移是一个 key 一个 key 搬的,当前的状态是:槽 100 里有一部分 key 已经被搬到 B 了,另一部分 key 还留在 A。
这时候客户端按照旧地图发请求去 A 访问 key1,A 一查:
- 如果
key1还在自己这里,那正常处理返回结果,没什么事; - 如果
key1已经被搬到 B 了,这时候该怎么办?
A 不能直接返回 MOVED,为啥?你想啊,MOVED 的语义是「这个槽永久归 B 了」,可实际情况是槽 100 里还有一部分 key 没搬完,这个槽整体上还是归 A 管。如果这时候让客户端更新地图,把整个槽 100 都改到 B,客户端下次访问留在 A 的那些 key 就全部找错地方了。
所以 Redis 设计了一个新的错误叫 ASK 重定向,错误消息长这样:
(error) ASK 100 192.168.1.2:6379
它的含义是:「这个 key 这一次你去 B 节点问问看,但这只是临时的,不要更新你的地图」。
客户端收到 ASK 之后会做两件事:
- 不更新本地地图,槽 100 的归属还是 A;
- 先给 B 发一个特殊的命令叫
ASKING,然后再发真正的请求。
为啥要先发个 ASKING 呢?因为这时候 B 还没正式接管槽 100,如果你直接发请求,B 反而会返回一个 MOVED 让你回去找 A(因为 B 觉得这个槽此刻不归自己)。ASKING 的作用就是告诉 B:「我知道这个槽你还没正式接管,但我是从 A 那边被 ASK 过来的,你就破个例给我处理一下这次请求吧」。B 收到 ASKING 之后就会临时处理一次,仅此一次,下次你还得重新发 ASKING。
所以 MOVED 和 ASK 的核心区别就在这里,小林用一句话帮你记住:
MOVED 是「永久搬家通知」,客户端要更新地图;ASK 是「临时借道通知」,客户端这一次跳过去,地图不动。
这个区别看似是细节,实际上是 Redis Cluster 能够在不停机的情况下完成数据迁移的关键。没有 ASK 重定向,迁移过程中的请求就没法正确处理了,整个集群动起来就会磕磕绊绊的。
# 4. 节点之间怎么同步信息?聊聊 Gossip 协议
到目前为止,我们讨论的都还停留在「客户端 ↔ 单个节点」这个层面。但别忘了 Cluster 是一堆节点组成的,这些节点之间也需要互相通信。
为啥需要通信呢?因为整个集群的状态是动态变化的:
- 有新节点加入进来
- 有节点挂掉下线
- 有槽在节点之间迁移
- 有主从切换发生
这些变化不能只有当事人知道,整个集群的每一个节点都得知道,不然就乱套了。
# 4.1 两种思路:中心化 vs 去中心化
要让所有节点都掌握集群的最新状态,大的思路上有两种。
第一种是中心化:专门搞一个(或一小撮)「管理员」角色,所有节点都向它汇报状态,所有节点也都从它那儿读最新状态。哨兵模式本质上就是这个路子。但中心化有个明显的问题:管理员自己如果挂了呢?虽然可以再给管理员做高可用,但整个架构会变得很复杂,而且维护这批管理员本身也是个成本。
第二种是去中心化:干脆不要管理员了,让节点之间直接互相聊天,各自把自己知道的东西告诉别人,这样最终大家的信息都会慢慢同步到一致。这种方式天生没有单点,也不需要额外的组件。
Redis Cluster 选的是第二种,它用的协议叫 Gossip(流言)协议。
# 4.2 Gossip 协议:一个八卦传播的故事
Gossip 这个词本来的意思就是「八卦、流言」,这个协议的工作方式和八卦传播简直一模一样,小林给你举个生活中的例子。
假设你们公司有 100 号人,某天你知道了一个爆炸性八卦。你会怎么传?你不会一个一个跑去跟全公司每个人讲,太累了。你只会随机找 2、3 个同事聊一下,然后这 2、3 个同事又各自去找 2、3 个同事,一传十十传百。用不了多久,整个公司就都知道了。
Gossip 协议就是这么工作的:每个节点不需要跟所有节点都通信,只要周期性地随机挑几个节点聊聊,把自己知道的集群状态告诉它们。这几个节点收到后又会把信息传给自己挑的几个邻居。经过若干轮之后,整个集群的所有节点都会收敛到一致的状态。
这种方式的好处是实现简单、没有单点,坏处是信息传播有一定的延迟,不像中心化那样「一喊全都知道」。但对于 Redis Cluster 这种对一致性要求没那么极致的场景来说,这点延迟是完全可以接受的。
# 4.3 Cluster 里的几种消息
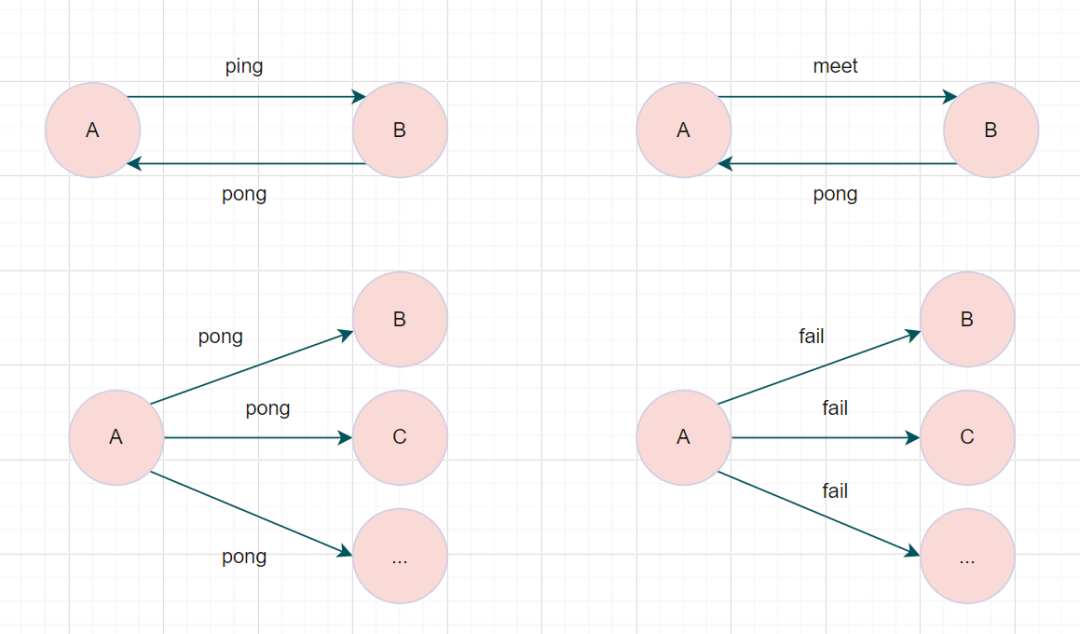
在 Redis Cluster 中,节点之间互相发送的 Gossip 消息主要有这么几种,名字起得都挺形象的:
- ping:节点每秒都会向随机选出的其他节点发 ping 消息,顺便把自己当前知道的集群状态(比如我知道哪些节点是活的、哪些槽归谁)一并塞在消息里带过去;
- pong:节点收到 ping 之后,回复一个 pong 消息作为确认,pong 里同样会带上自己所知道的集群状态;
- meet:当你往集群里加一台新节点时,要让集群里某台老节点主动给新节点发一个 meet 消息,相当于「打个招呼,欢迎加入本集群」。新节点收到 meet 之后就会和发消息方建立连接,然后顺着 Gossip 网络把集群里其他的节点也「认识」一遍;
- fail:当某个节点被判定为彻底挂了,会有节点向整个集群广播一个 fail 消息,告诉大家「这家伙真的不行了,大家把它的状态更新成下线吧」。
你可能会注意到,ping 和 pong 每次都带上「自己所知道的集群状态」,这就是信息不断扩散、不断对齐的过程。每次「闲聊」都在交换情报,慢慢地整个集群的视图就统一了。
# 4.4 集群总线和 16379 端口
还有一个小细节值得提一嘴:集群里节点之间的通信走的不是我们平时连接 Redis 用的那个端口(比如 6379),而是一个专门的集群总线端口,叫做 cluster bus,约定就是「业务端口 + 10000」。所以如果你配的 Redis 端口是 6379,那节点之间的通信端口就是 16379。
这意味着你在部署 Cluster 时,防火墙上两个端口都要放行。忘了放 16379 是新手经常踩的坑,会出现节点之间看起来谁也连不上谁的诡异现象,搭集群怎么都搭不起来。
# 4.5 Gossip 不是没有代价
Gossip 听起来很美,但它也不是没有代价的。最主要的代价是:Gossip 的消息量会随节点数量的增长而急剧增长,大概是平方级的关系。
为啥是平方级呢?你想想看,每个节点都要跟其他节点通信,而且每条消息里还要携带一份自己所知道的集群状态。节点越多,每条消息体越大,每秒发出的消息总数也越多,累加起来带宽开销就会很夸张。
这也是为什么 Redis 官方建议 Cluster 主节点的数量不要超过 1000 个。超过这个规模,光是节点之间互相「打招呼」的流量就足够把网络搞得很紧张,甚至影响正常业务请求。
# 5. 节点挂了怎么办?聊聊故障转移
到目前为止,我们讲的都是「一切正常」的情况。但实际生产环境里,机器挂掉是家常便饭,磁盘坏、网线松、内核 panic,五花八门。一个号称高可用的集群方案,必须要能在节点挂掉的时候自动恢复服务,这就是我们说的故障转移(failover)。
# 5.1 先铺垫一下:Cluster 里的主从关系
在讲故障转移之前,我们得先明确一件事:Redis Cluster 里的每个主节点,都可以配一个或多个从节点。
这些从节点平时在干什么呢?它们其实就是对应主节点的「影子」,通过主从复制不断把主节点的数据同步过来,保证自己这边的数据和主节点尽量保持一致。
但是注意,这些从节点默认是不对外提供读写服务的。你如果直接连上一个从节点去 GET 一个 key,它会返回一个 MOVED 让你回去找主节点(后面小节会讲一个叫 READONLY 的命令可以改变这个行为)。所以你可以把从节点理解为「热备」:平时就在那儿待命,主节点出事了立马顶上去。
这就是为什么「3 主 3 从」是 Redis Cluster 最小的推荐部署规模:3 个主节点分摊 16384 个槽负责读写,每个主节点各配一个从节点做热备。任何一个主节点挂了,对应的从节点都能立刻顶上。
# 5.2 怎么发现一个节点挂了?pfail 和 fail 两阶段
我们前面说过,节点之间会不断地互相发 ping。如果某个节点发出去的 ping 在约定时间(由参数 cluster-node-timeout 控制,默认 15 秒)内都没收到对方的回复,它就会心里嘀咕:「这哥们是不是挂了?」
注意这里是「心里嘀咕」,不是「对外宣布」。因为有可能只是我跟他之间的网络闪了一下,别的节点其实还连得上。这种单个节点单方面的判断,在 Cluster 里叫 pfail 状态(probably failed,可能挂了),也就是我们常说的主观下线。
然后这个 pfail 状态会随着 Gossip 消息慢慢传到集群里别的节点。如果集群里半数以上持有槽的主节点都认为这个节点处于 pfail 状态(也就是大家都觉得它挂了,不是我一个人闹脾气),那它的状态就会升级为 fail 状态,也叫客观下线。这时候才会有节点出来广播一条 fail 消息,告诉整个集群:「这家伙真没了,启动故障转移吧。」
为啥要搞主观下线、客观下线两个阶段?就是为了防止误判。网络抖动是常有的事,单靠一个节点的判断就把别人拉下马,太草率了。多个节点达成共识之后再下线,稳妥得多。
# 5.3 选出一个新主:Cluster 的选举机制
挂的如果是从节点,其实没啥大事,顶多就是少了一个备胎,对读写服务没有直接影响。但如果挂的是主节点,那问题就严重了:这个主节点负责的那部分槽,现在没人管了,客户端访问那些槽都会失败。
这时候就得从它的从节点里面选一个出来当新主。怎么选呢?Redis Cluster 用的是类似 Raft 的投票机制,流程大致是这样的。
第一步,资格检查。
不是所有从节点都有资格参选。如果一个从节点跟主节点已经失联太久(说明它的数据可能已经很陈旧了),那它就没资格参与这次选举。Redis 会根据 cluster-replica-validity-factor 这个参数来判断「失联多久算太久」。
第二步,排队等发起选举。
有资格的从节点不会一股脑全都跳出来喊「选我选我」,而是会按照自己和主节点的数据同步进度排个队:复制得越新的从节点,等待的时间越短。
这么做很聪明,你想想看:数据最新的那个从节点优先发起选举、也最有可能当选,这样就能把故障切换后数据丢失的风险降到最低。
第三步,发起选举,请求投票。
等待时间到了之后,从节点就会向集群里所有持有槽的主节点拉票:「我想竞选槽 X 的新主,请你们投我一票」。
第四步,收集选票。
这里有一个重要的规则:只有持有槽的主节点才有投票权,从节点和不持有槽的节点都没有投票权。这就有点像国家议会里只有议员才能投票一样,要有一定「身份」才行。每个主节点在一轮选举里只能投一票,投给第一个来拉票的合格候选人。
第五步,成为新主。
如果某个候选从节点拿到了半数以上主节点的票(比如 5 个主节点里有 3 票),它就当选了。当选之后,它会把自己从「从节点」升级成「主节点」,然后通过 Gossip 广播一条消息告诉整个集群:「这些槽现在归我管了」。其他节点收到之后更新自己的本地信息,客户端下次再访问这些槽时,会通过 MOVED 重定向被纠正到新主节点,故障转移就完成了。
# 5.4 一个必须要提的「但是」:Cluster 会丢数据吗?
讲到这儿,你可能以为 Cluster 就是万能的。但是小林必须提醒你一件事:Redis Cluster 的主从复制是异步的,所以故障转移过程中是有可能丢数据的。
异步是什么意思呢?就是主节点处理完一个写命令之后,会立刻返回成功给客户端,然后才慢悠悠地把这个写命令同步给从节点。这中间有一个极小的时间窗口。
想象一下这个极端情况:
- 客户端向主节点写入一条数据,主节点写完内存,返回 OK;
- 主节点还没来得及把这条数据同步给从节点,就突然宕机了;
- 从节点被选举成新主,但它手里根本没有这条数据;
- 客户端再来查,发现数据不见了。
这就是典型的故障转移导致的数据丢失。所以在架构选型的时候你心里要有一个清醒的认识:Redis Cluster 在 CAP 理论里是偏向 AP 的,它为了可用性和分区容忍性,牺牲了一部分强一致性。
对于绝大多数缓存场景,这点损失是完全可以接受的。但对于一定要强一致的场景(比如涉及钱的扣款、库存扣减),你就得另想办法了,比如配合数据库做最终一致,或者上 ZooKeeper、etcd 这类强一致的协调服务。

# 6. 初学者最容易踩的两个坑
讲到这里,Redis Cluster 的核心原理其实已经讲完了。但小林知道,原理懂了不代表你动手就能顺利用起来。这一节挑两个初学者第一次用 Cluster 就会撞到的坑,提前给你打个预防针。
# 6.1 多 key 操作报 CROSSSLOT 错误
这是第一次用 Cluster 的人最常见的一个懵逼瞬间。你在单机 Redis 上写得好好的代码:
MSET user:1:name xiaolin user:1:age 18
换到 Cluster 环境下,直接报错:
(error) CROSSSLOT Keys in request don't hash to the same slot
这是为啥?因为 user:1:name 和 user:1:age 算出来的 CRC16 值完全不一样,很可能落在不同的槽里,而不同的槽又很可能归不同的节点管。一个命令要同时操作两个节点上的数据,Cluster 做不到,只能报错。
这个问题 Redis 官方也知道,所以给了一个解决办法叫 Hash Tag:你可以在 key 里用花括号 {} 括起一段,只有花括号里的部分会参与 CRC16 计算。看例子:
MSET {user:1}:name xiaolin {user:1}:age 18
这两个 key 在计算槽号时,只会看 user:1 这一段,所以它们算出来的槽号一定是一样的,也就一定会落在同一个节点上,MSET 就能正常工作了。
同样的道理也适用于事务(MULTI/EXEC)、Lua 脚本、pipeline 这些涉及多 key 的场景:如果你希望这些多 key 操作能在 Cluster 下正确工作,记得把相关的 key 加上统一的 Hash Tag,让它们绑在一个槽里。
# 6.2 从节点默认不提供读服务
第二个坑是关于读写分离的。
很多小伙伴听说 Cluster 有从节点,自然而然地以为「那我可以把读请求打到从节点上做读写分离啊」,结果发现连上从节点 GET 一个 key,直接被 MOVED 回主节点了,很郁闷。
这是因为 Cluster 里的从节点默认是不处理读请求的,它的唯一任务就是等主节点挂了之后顶上去。如果你确实想让从节点分担一部分读压力,需要在客户端侧先对从节点发一个 READONLY 命令,告诉它:「我知道从这里读可能读到稍微旧一点的数据,我能接受」。发过 READONLY 之后,后续的读请求就会在这个从节点上正常处理了。
不过要提醒你一句,从节点的数据是异步同步过来的,和主节点之间可能有短暂的延迟,所以对数据新鲜度要求高的业务,还是老老实实走主节点吧。
# 7. 加餐:为什么哈希槽的数量是 16384?
前面卖了个关子,这一节我们把这个「灵魂疑问」解决掉。
其实这个问题当年在 GitHub 上就有人去问过 Redis 的作者 antirez,我们来看看他是怎么回答的:
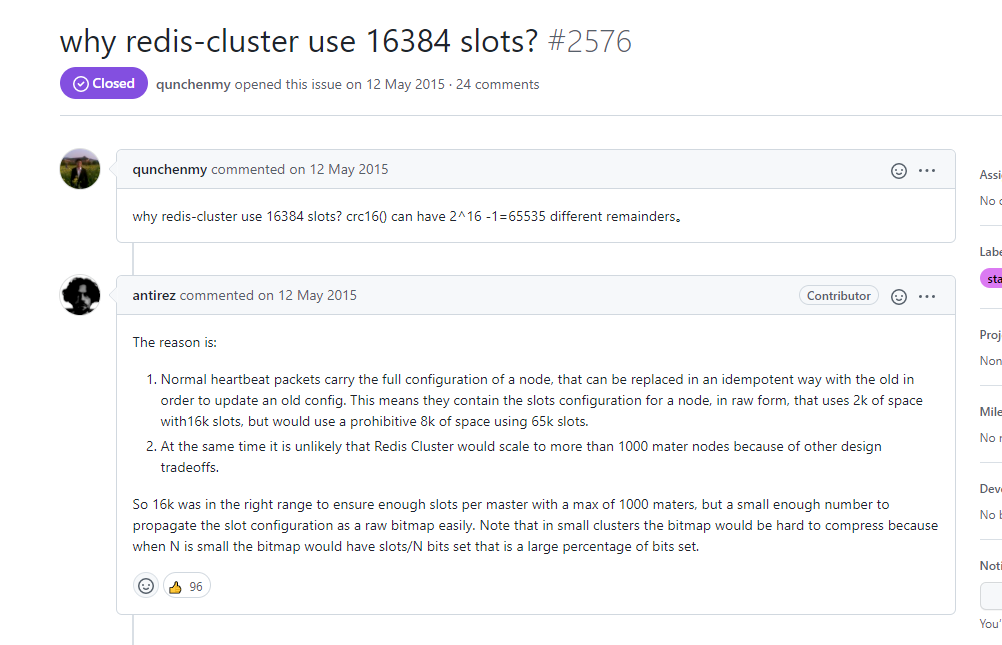
antirez 给的理由主要跟网络传输效率有关。
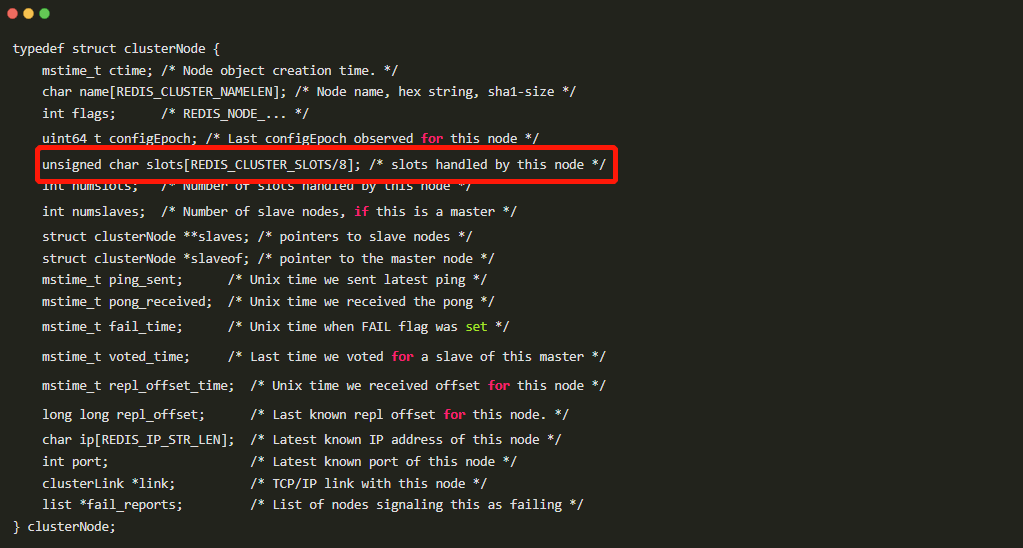
我们前面讲 Gossip 的时候说过,节点之间每秒都要通过 ping/pong 交换集群的状态信息。其中一个很重要的内容就是「我这个节点负责哪些槽」。这个信息在节点里面是用一个**位图(bitmap)**来存的:每个槽占一个 bit,这个 bit 是 1 表示「这个槽归我管」,是 0 表示「不归我管」。
那如果槽的数量是 65536,这个位图需要多少空间呢?
65536 bit / 8 = 8192 字节 = 8 KB
也就是说,每发一次 ping 都要带着一个 8KB 的位图到处跑。
而如果槽的数量是 16384,情况就好多了:
16384 bit / 8 = 2048 字节 = 2 KB
一下子就从 8KB 降到了 2KB,省了 6KB。别小看这 6KB,Gossip 是每秒都在跑的,集群里节点越多这个差距就越放大,带宽压力明显会小很多。
那你可能又会问:既然位图越小越省带宽,为啥不用更小的 8192 呢?8192 个槽对应的位图才 1KB,不是更省?
这就涉及到另一个约束了:槽的数量要大于集群中主节点的数量,而且要有足够的富余度来保证负载均衡。因为 CRC16 算出来的结果并不是绝对均匀的,槽的数量如果太少,就容易出现有的节点分到的 key 多、有的节点分到的 key 少的情况。
antirez 在回复里也说了,他认为 Redis Cluster 最多支撑到约 1000 个主节点这个规模,16384 个槽平均分给 1000 个节点,每个节点大约有 16 个槽,已经足以保证负载的均衡了;而 8192 就稍微有点紧。
综合考虑「带宽消耗」和「负载均衡」这两方面,antirez 最终选择了 16384 这个数字。它恰好能覆盖常见的集群规模,同时位图只有 2KB,带宽开销也能接受,算是一个工程上的折中。
顺便提一个小细节,Redis 源码里实际计算槽号用的是位运算:
slot = CRC16(key) & 16383
这是因为 x % (2^n) 等价于 x & (2^n - 1),而 16384 正好是 2 的 14 次方,16383 就是 2^14 - 1,用 & 比用 % 快一些。这也是为什么槽的数量要选一个 2 的幂次方。
# 8. 总结一下
这篇文章讲了挺多内容,小林最后用几句话帮你把主线串起来。
Redis Cluster 要解决的核心问题,是单机 Redis 的内存有上限,必须把数据分散到多台机器上。这是它存在的根本理由。
数据怎么分? 通过在 key 和机器之间加一层「哈希槽」:key → CRC16 → 16384 个槽 → 节点。好处是扩缩容时只搬槽不搬 key,迁移成本可控。
客户端怎么找到数据? Smart Client 在本地缓存一份「槽 → 节点」的地图,先本地算槽号再直接发请求,一次命中。如果地图过期,服务端通过 MOVED 通知客户端「永久搬家」;如果槽正在迁移中,则通过 ASK 做「临时借道」。
节点之间怎么同步状态? 用 Gossip 协议,每个节点周期性地跟其他节点「八卦」自己知道的集群状态,最终整个集群的信息会收敛到一致。代价是消息量随节点数平方级增长,所以规模不建议超过 1000 主节点。
节点挂了怎么办? 通过 pfail、fail 两阶段判断是否真的下线,然后从故障主节点的从节点里,按数据新鲜度优先级发起选举,半数以上主节点投票赞成即可当选新主。注意主从是异步复制的,故障转移有丢数据的风险,所以 Cluster 整体偏 AP 而不是 CP。
动手前的两个坑 要记住:多 key 操作要用 Hash Tag 把 key 绑到同一个槽,从节点读要先发 READONLY。
最后小林留一个问题给你思考:如果让你从零设计一个分布式 KV 存储,你会借鉴 Redis Cluster 的哪些点,又会改掉哪些点呢?欢迎在评论区聊聊你的想法。
最新的图解文章都在公众号首发,别忘记关注哦!!如果你想加入百人技术交流群,扫码下方二维码回复「加群」。
