# 去哪儿 Java 面试

大家好,我是小林。
这周跟大家说了美团、京东这些互联网一线大厂校招开奖情况,有同学就问我,有没有二线互联网公司的开奖情况呀?
正好,今天看到「去哪儿」开奖了,去哪儿虽然属于互联网中厂,但是薪资开的也是比较给力的,目前看到开奖有 2 个档次,年薪也是在 35w 左右。
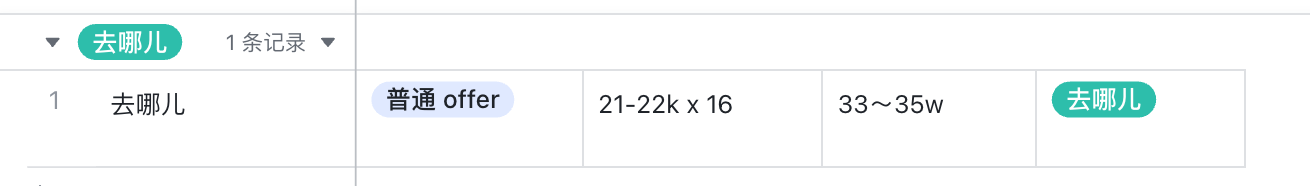
- 22k x 16 = 35w
- 21k x 16 = 33w
现在能看到爆料薪资比较少,sp、ssp 的档位薪资还不清楚。
去哪儿的校招面试的流程是一二三面一起的,一面完了就在会议里面一直等待,等到二面面试官来,最后也是等HR来,整个流程就算完成,一共会持续大概三个多小时。
- 一面的面试风格是偏向八股,比如Java、数据库、计算机基础等,会要求写一个算法
- 二面的面试风格是偏向项目和场景题,比如项目中有什么难点,也有可能也会写一个算法
- 三面是 HR面,考察一些通用性问题,比如职业规划,优缺点,最大困难这些
这次,跟大家分享今年去哪儿秋招的后端开发的面经,是一面面经,以技术拷打为主。
# 去哪儿一面
# Java 线程状态有哪些?
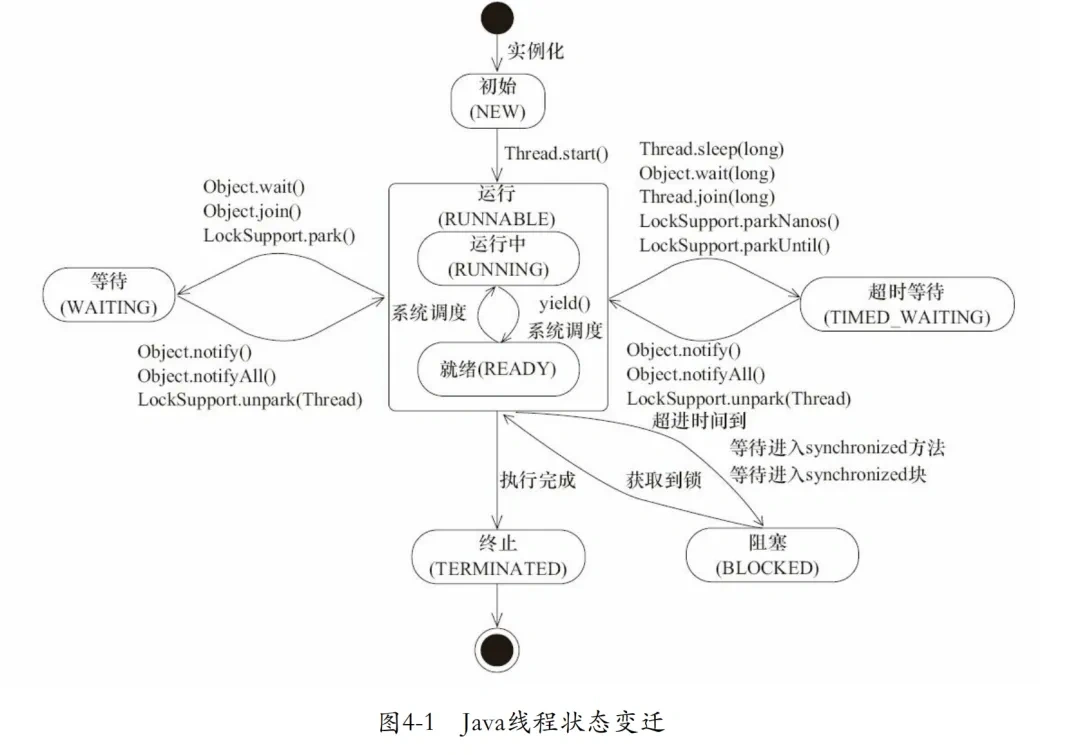
源自《Java并发编程艺术》 java.lang.Thread.State枚举类中定义了六种线程的状态,可以调用线程Thread中的getState()方法获取当前线程的状态。
| 线程状态 | 解释 |
|---|---|
| NEW | 尚未启动的线程状态,即线程创建,还未调用start方法 |
| RUNNABLE | 就绪状态(调用start,等待调度)+正在运行 |
| BLOCKED | 等待监视器锁时,陷入阻塞状态 |
| WAITING | 等待状态的线程正在等待另一线程执行特定的操作(如notify) |
| TIMED_WAITING | 具有指定等待时间的等待状态 |
| TERMINATED | 线程完成执行,终止状态 |
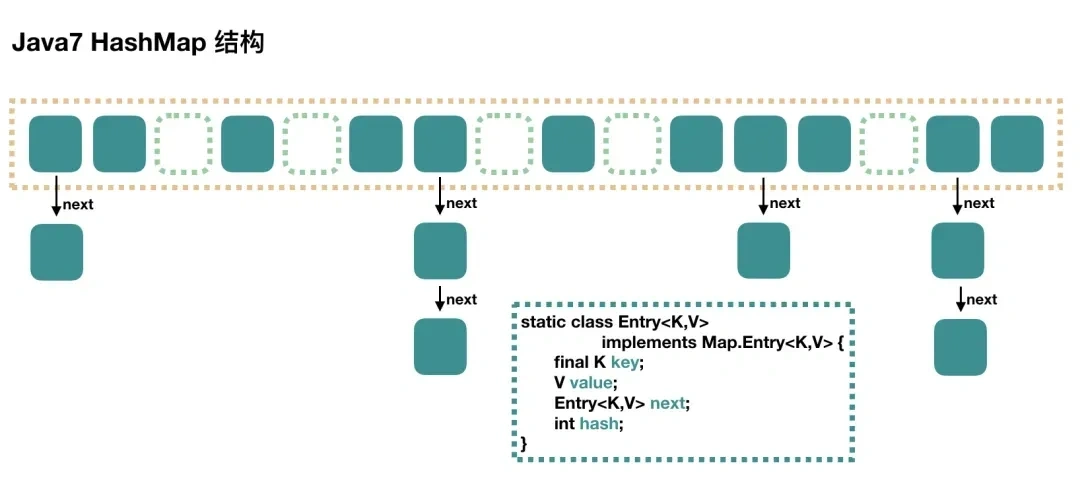
# hashmap底层结构说一下?
在 JDK 1.7 版本之前, HashMap 数据结构是数组和链表,HashMap通过哈希算法将元素的键(Key)映射到数组中的槽位(Bucket)。如果多个键映射到同一个槽位,它们会以链表的形式存储在同一个槽位上,因为链表的查询时间是O(n),所以冲突很严重,一个索引上的链表非常长,效率就很低了。
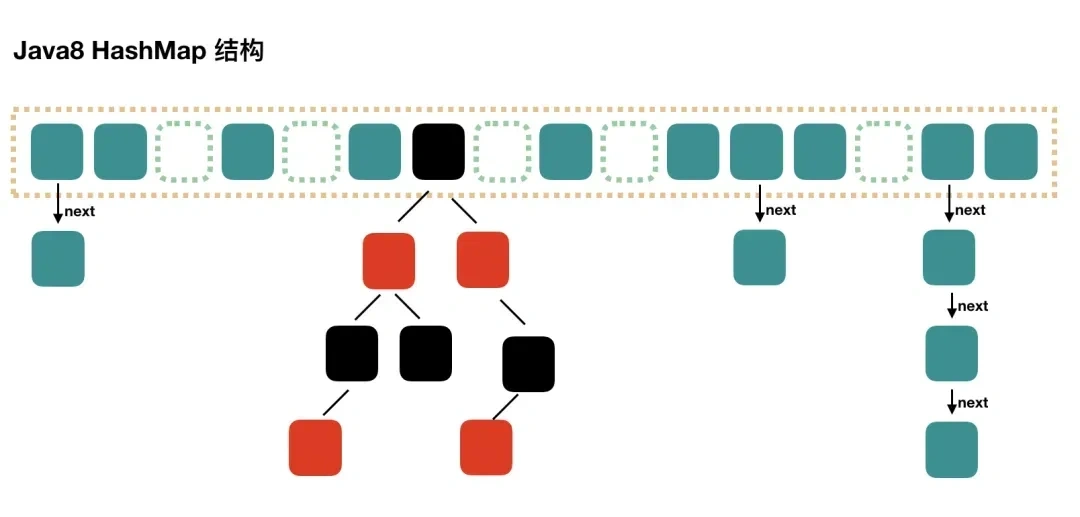
 所以在 JDK 1.8 版本的时候做了优化,当一个链表的长度超过8的时候就转换数据结构,不再使用链表存储,而是使用红黑树,查找时使用红黑树,时间复杂度O(log n),可以提高查询性能,但是在数量较少时,即数量小于6时,会将红黑树转换回链表。
所以在 JDK 1.8 版本的时候做了优化,当一个链表的长度超过8的时候就转换数据结构,不再使用链表存储,而是使用红黑树,查找时使用红黑树,时间复杂度O(log n),可以提高查询性能,但是在数量较少时,即数量小于6时,会将红黑树转换回链表。
# hashmap在并发时怎么去解决?
hashmap不是线程安全的,hashmap在多线程会存在下面的问题:
- JDK 1.7 HashMap 采用数组 + 链表的数据结构,多线程背景下,在数组扩容的时候,存在 Entry 链死循环和数据丢失问题。
- JDK 1.8 HashMap 采用数组 + 链表 + 红黑二叉树的数据结构,优化了 1.7 中数组扩容的方案,解决了 Entry 链死循环和数据丢失问题。但是多线程背景下,put 方法存在数据覆盖的问题。
如果要保证线程安全,可以通过这些方法来保证:
- 多线程环境可以使用Collections.synchronizedMap同步加锁的方式,还可以使用HashTable,但是同步的方式显然性能不达标,而ConurrentHashMap更适合高并发场景使用。
- ConcurrentHashmap在JDK1.7和1.8的版本改动比较大,1.7使用Segment+HashEntry分段锁的方式实现,1.8则抛弃了Segment,改为使用CAS+synchronized+Node实现,同样也加入了红黑树,避免链表过长导致性能的问题。
# HTTP的几个版本的区别?
HTTP/2 相比 HTTP/1.1 性能上的改进:
- 头部压缩:HTTP/2 会压缩头(Header)如果你同时发出多个请求,他们的头是一样的或是相似的,那么,协议会帮你消除重复的部分。这就是所谓的 HPACK 算法:在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
- 二进制格式:HTTP/2 不再像 HTTP/1.1 里的纯文本形式的报文,而是全面采用了二进制格式,头信息和数据体都是二进制,并且统称为帧(frame):头信息帧(Headers Frame)和数据帧(Data Frame)。这样虽然对人不友好,但是对计算机非常友好,因为计算机只懂二进制,那么收到报文后,无需再将明文的报文转成二进制,而是直接解析二进制报文,这增加了数据传输的效率。
- 并发传输:引出了 Stream 概念,多个 Stream 复用在一条 TCP 连接。解决了HTTP/1.1 队头阻塞的问题:
- 服务器主动推送资源:HTTP/2 还在一定程度上改善了传统的「请求 - 应答」工作模式,服务端不再是被动地响应,可以主动向客户端发送消息。
# redis的基本数据结构
Redis 提供了丰富的数据类型,常见的有五种数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
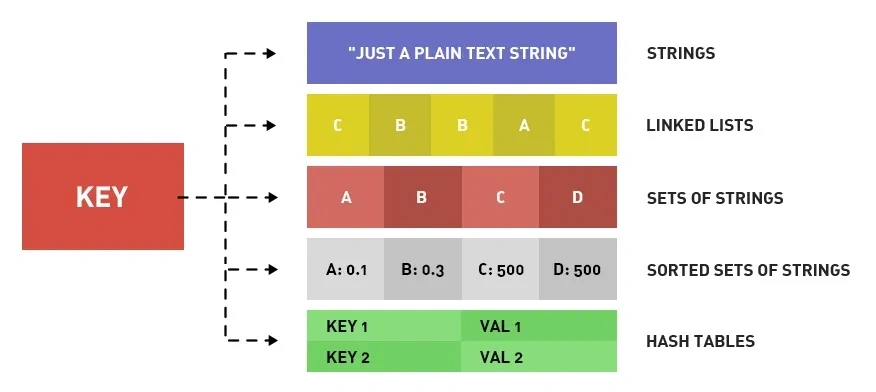
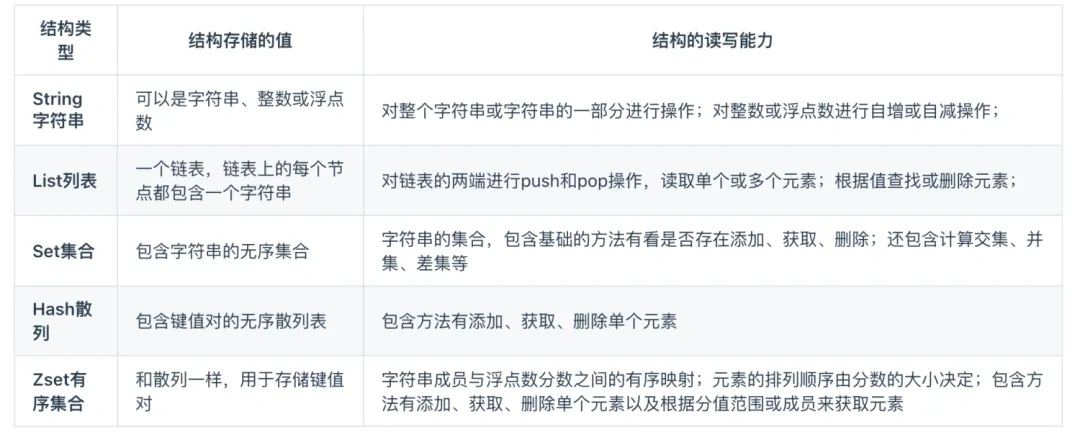
随着 Redis 版本的更新,后面又支持了四种数据类型:BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增)。Redis 五种数据类型的应用场景:
- String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
- List 类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
- Hash 类型:缓存对象、购物车等。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
- Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
- BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
- GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
# Mysql索引了解吗?
MySQL InnoDB 引擎是用了B+树作为了索引的数据结构。
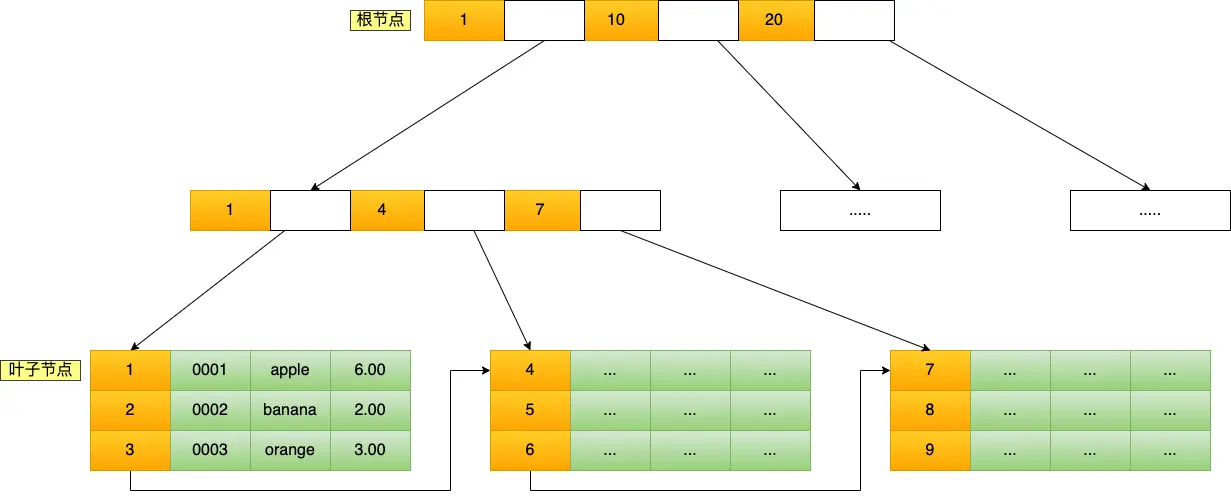
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键顺序存放的。每一层父节点的索引值都会出现在下层子节点的索引值中,因此在叶子节点中,包括了所有的索引值信息,并且每一个叶子节点都有两个指针,分别指向下一个叶子节点和上一个叶子节点,形成一个双向链表。
主键索引的 B+Tree 如图所示:
比如,我们执行了下面这条查询语句:
select * from product where id= 5;
这条语句使用了主键索引查询 id 号为 5 的商品。查询过程是这样的,B+Tree 会自顶向下逐层进行查找:
- 将 5 与根节点的索引数据 (1,10,20) 比较,5 在 1 和 10 之间,所以根据 B+Tree的搜索逻辑,找到第二层的索引数据 (1,4,7);
- 在第二层的索引数据 (1,4,7)中进行查找,因为 5 在 4 和 7 之间,所以找到第三层的索引数据(4,5,6);
- 在叶子节点的索引数据(4,5,6)中进行查找,然后我们找到了索引值为 5 的行数据。
数据库的索引和数据都是存储在硬盘的,我们可以把读取一个节点当作一次磁盘 I/O 操作。那么上面的整个查询过程一共经历了 3 个节点,也就是进行了 3 次 I/O 操作。
B+Tree 存储千万级的数据只需要 3-4 层高度就可以满足,这意味着从千万级的表查询目标数据最多需要 3-4 次磁盘 I/O,所以B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率很高,因为即使在数据量很大的情况,查询一个数据的磁盘 I/O 依然维持在 3-4次。
# MVCC 原理介绍一下?
MVCC允许多个事务同时读取同一行数据,而不会彼此阻塞,每个事务看到的数据版本是该事务开始时的数据版本。这意味着,如果其他事务在此期间修改了数据,正在运行的事务仍然看到的是它开始时的数据状态,从而实现了非阻塞读操作。
对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 Read View 来实现的,它们的区别在于创建 Read View 的时机不同,大家可以把 Read View 理解成一个数据快照,就像相机拍照那样,定格某一时刻的风景。
- 「读提交」隔离级别是在「每个select语句执行前」都会重新生成一个 Read View;
- 「可重复读」隔离级别是执行第一条select时,生成一个 Read View,然后整个事务期间都在用这个 Read View。
Read View 有四个重要的字段:
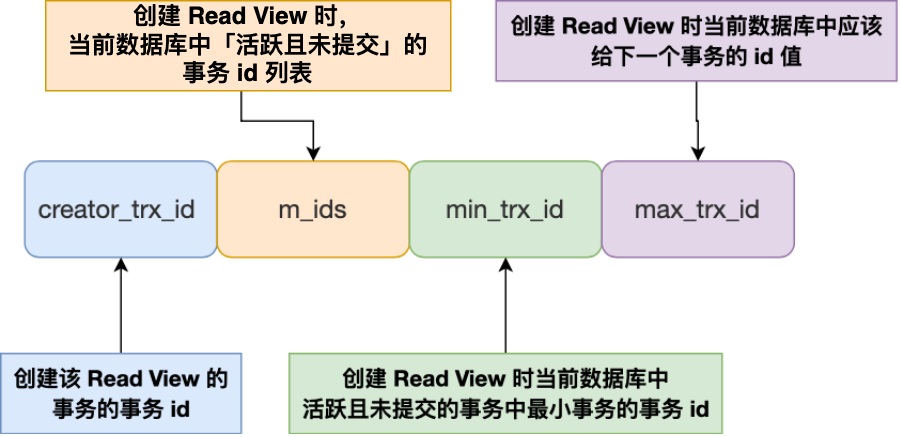
- m_ids :指的是在创建 Read View 时,当前数据库中「活跃事务」的事务 id 列表,注意是一个列表,“活跃事务”指的就是,启动了但还没提交的事务。
- min_trx_id :指的是在创建 Read View 时,当前数据库中「活跃事务」中事务 id 最小的事务,也就是 m_ids 的最小值。
- max_trx_id :这个并不是 m_ids 的最大值,而是创建 Read View 时当前数据库中应该给下一个事务的 id 值,也就是全局事务中最大的事务 id 值 + 1;
- creator_trx_id :指的是创建该 Read View 的事务的事务 id。
对于使用 InnoDB 存储引擎的数据库表,它的聚簇索引记录中都包含下面两个隐藏列:
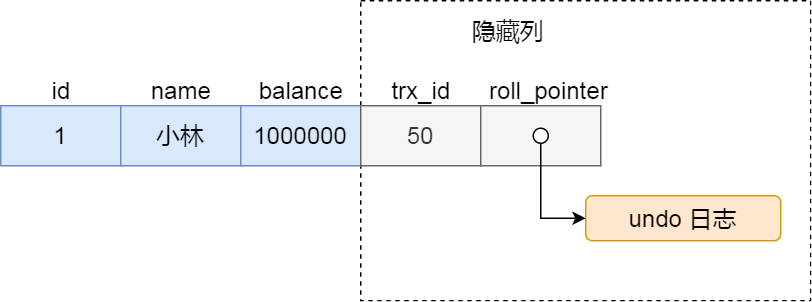
- trx_id,当一个事务对某条聚簇索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;
- roll_pointer,每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
在创建 Read View 后,我们可以将记录中的 trx_id 划分这三种情况:
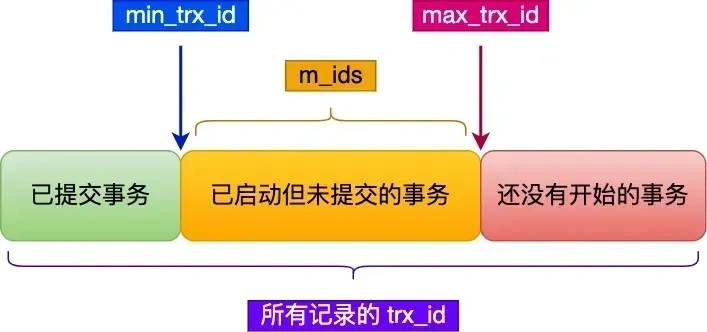
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
- 如果记录的 trx_id 值小于 Read View 中的 min_trx_id 值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。
- 如果记录的 trx_id 值大于等于 Read View 中的 max_trx_id 值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id 之间,需要判断 trx_id 是否在 m_ids 列表中:
- 如果记录的 trx_id 在 m_ids 列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 不在 m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
# 手撕
- 算法:两两交换链表中的节点
对了,最新的互联网大厂后端面经都会在公众号首发,别忘记关注哦!!如果你想加入百人技术交流群,扫码下方二维码回复「加群」。
