# 4399 Java 面试

大家好,我是小林。
4399 小游戏相信都是大家的童年回忆,每次上电脑课,防着老师悄悄打开 4399 网页,玩转上面各种琳琅满目的小游戏,当时最常同学友一起玩的是死神vs火影,两个人在键盘上敲的非常激烈,以至于被老师发现了,老师就直接拔网线了。
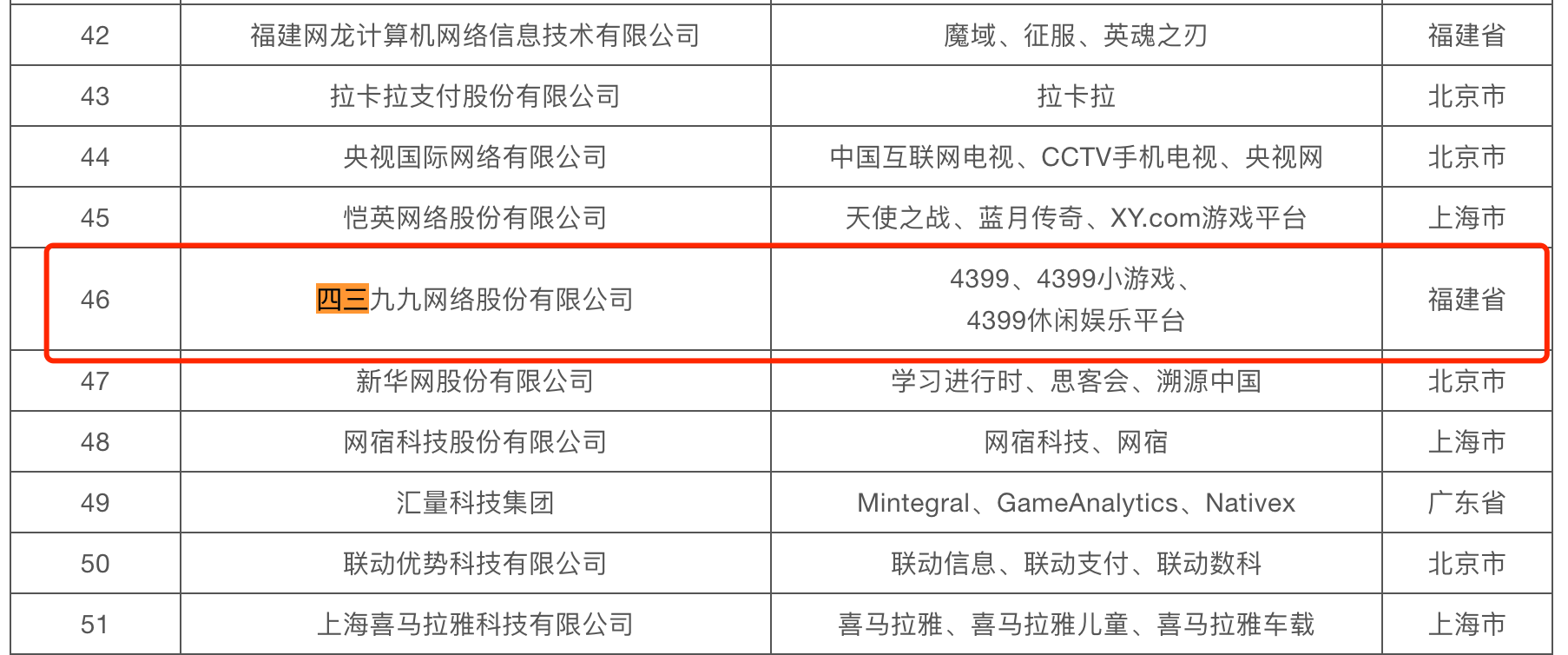
如果长大之后没有在关注 4399 小游戏的同学,估计都以为 4399 销声匿迹了,其实人家不光活着,而且活得还挺好,并且长期在互联网百强企业名单里,在 2024 年百强企业名单里,4399 排名 46。
现在 4399 公司规模也有上千人了,总部在厦门,基本上有双休,工作时间是早上九点到下午六点,但是毕竟是游戏公司,加班的情况可能还是存在的。

我看了一下 4399 开发岗位的校招薪资,大概范围是 16k~19k x 13,也就是年薪在 20w~ 25w,薪资在二线城市还是比较有竞争力的。
这次我们来看看 4399 Java 岗的校招面经,这次是一面,问的还是比较基础,感觉像八股问答赛,没有算法,问完八股就结束了,流程大概 20 多分钟。

# 4399一面
# java是怎么学习的?
学校有开设Java 的课程,除此之外,还看过《Java并发编程的艺术》、《深入理解Java虚拟机》、《Spring5 实战》、《MySQL技术内幕》、《Redis设计与实现》相关的书籍,同时为了增加Java 开发能力,做过 xxx 项目。
# java语言的特点是什么?
主要有以下的特点:
- 平台无关性:Java的“编写一次,运行无处不在”哲学是其最大的特点之一。Java编译器将源代码编译成字节码(bytecode),该字节码可以在任何安装了Java虚拟机的系统上运行。
- 面向对象:Java是一门严格的面向对象编程语言,几乎一切都是对象。面向对象编程特性使得代码更易于维护和重用,包括类、对象、继承、多态、抽象和封装。
- 内存管理:Java有自己的垃圾回收机制,自动管理内存和回收不再使用的对象。这样,开发者不需要手动管理内存,从而减少内存泄漏和其他内存相关的问题。
# final关键字怎么用
final关键字可以用来修饰类、方法和变量,具有不同的作用:
- 修饰类:将
final关键字放在类的定义前,如final class MyClass {...}。被final修饰的类不能被继承。这通常用于创建一些不希望被修改或扩展的类,例如 Java 中的String类就是final类。
final class FinalClass {
// 类的成员和方法
}
// 以下代码将无法编译
// class SubClass extends FinalClass {}
- 修饰方法:将
final关键字放在方法的声明前,如public final void myMethod() {...}。被final修饰的方法不能被子类重写。这可以确保方法的实现不被修改,通常用于保证一些关键方法的行为在子类中不会改变。
class BaseClass {
public final void finalMethod() {
System.out.println("This is a final method.");
}
}
class SubClass extends BaseClass {
// 以下代码将无法编译
// public void finalMethod() {
// System.out.println("Trying to override final method.");
// }
}
- 修饰变量:将
final关键字放在变量的声明前,如final int myVariable = 10;。对于基本数据类型,被final修饰的变量一旦赋值就不能再修改其值;对于引用数据类型(如对象和数组),被final修饰的变量一旦引用了一个对象或数组,就不能再引用其他对象或数组,但可以修改对象或数组的内部状态。
// 修饰基本数据类型
final int number = 5;
// 以下代码将无法编译
// number = 10;
// 修饰对象
final StringBuilder sb = new StringBuilder("Hello");
sb.append(", World"); // 允许修改对象的内部状态
// 以下代码将无法编译
// sb = new StringBuilder("Goodbye");
- 修饰参数:在方法的参数列表中使用
final关键字,如public void myMethod(final int parameter) {...}。被final修饰的参数在方法内部不能被修改。这可以防止在方法中不小心修改了传入的参数值。
public void printValue(final int value) {
// 以下代码将无法编译
// value = 10;
System.out.println(value);
}
# 使用hashmap时,如果只重写了equals没有重写hashcode会出现什么问题?
HashMap 存储元素是基于哈希表的原理。它通过 hashCode 方法计算元素的哈希值,将元素存储在对应的哈希桶中。当查找元素时,首先根据 hashCode 找到对应的哈希桶,然后在该桶中使用 equals 方法精确查找元素。
如果只重写了 equals 方法而未重写 hashCode 方法,那么即使两个对象在逻辑上相等(根据 equals 方法的判断),它们的 hashCode 可能不同,这样会导致两个逻辑上相等的对象可能被存储在 HashMap 的不同哈希桶中,因为它们的 hashCode 不同。
当尝试根据键来查找元素时,可能无法找到元素。因为 HashMap 首先根据 hashCode 找到哈希桶,而由于 hashCode 不同,会在错误的哈希桶中查找,导致查找失败,即使 equals 方法认为它们相等。
为了避免这个问题,当重写 equals 方法时,应该同时重写 hashCode 方法,以保证对象的逻辑相等性和存储查找的一致性。
# 深拷贝和浅拷贝的区别是什么?
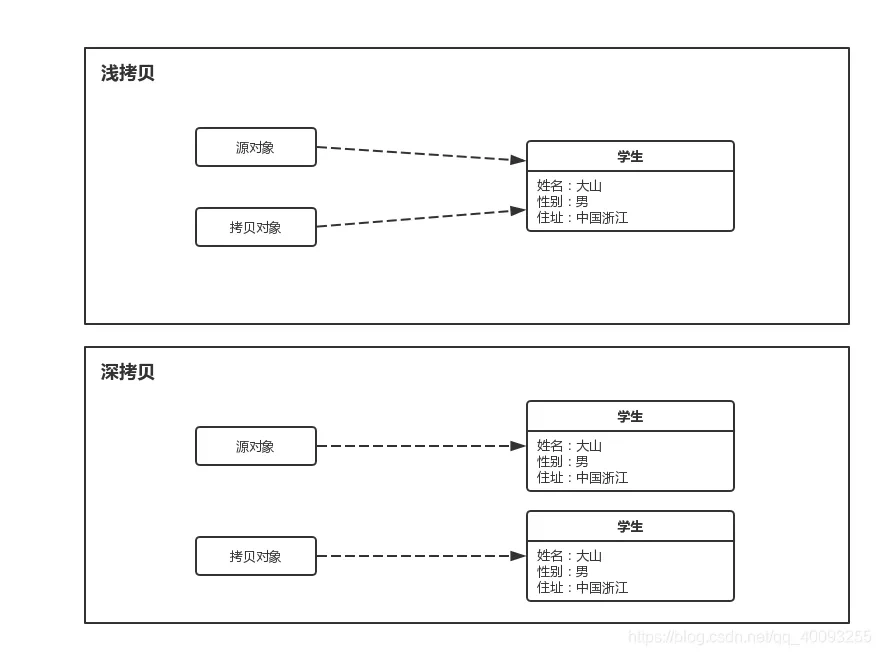
- 浅拷贝是指只复制对象本身和其内部的值类型字段,但不会复制对象内部的引用类型字段。换句话说,浅拷贝只是创建一个新的对象,然后将原对象的字段值复制到新对象中,但如果原对象内部有引用类型的字段,只是将引用复制到新对象中,两个对象指向的是同一个引用对象。
- 深拷贝是指在复制对象的同时,将对象内部的所有引用类型字段的内容也复制一份,而不是共享引用。换句话说,深拷贝会递归复制对象内部所有引用类型的字段,生成一个全新的对象以及其内部的所有对象。
# java创建对象有哪些方式?
创建对象的方式有多种,常见的包括:
- 使用new关键字:通过new关键字直接调用类的构造方法来创建对象。
MyClass obj = new MyClass();
- 使用Class类的newInstance()方法:通过反射机制,可以使用Class类的newInstance()方法创建对象。
MyClass obj = (MyClass) Class.forName("com.example.MyClass").newInstance();
- 使用Constructor类的newInstance()方法:同样是通过反射机制,可以使用Constructor类的newInstance()方法创建对象。
Constructor<MyClass> constructor = MyClass.class.getConstructor();
MyClass obj = constructor.newInstance();
- 使用clone()方法:如果类实现了Cloneable接口,可以使用clone()方法复制对象。
MyClass obj1 = new MyClass();
MyClass obj2 = (MyClass) obj1.clone();
- 使用反序列化:通过将对象序列化到文件或流中,然后再进行反序列化来创建对象。
// SerializedObject.java
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("object.ser"));
out.writeObject(obj);
out.close();
// DeserializedObject.java
ObjectInputStream in = new ObjectInputStream(new FileInputStream("object.ser"));
MyClass obj = (MyClass) in.readObject();
in.close();
# 线程的创建方式有哪些?
1、继承Thread类
这是最直接的一种方式,用户自定义类继承java.lang.Thread类,重写其run()方法,run()方法中定义了线程执行的具体任务。创建该类的实例后,通过调用start()方法启动线程。
class MyThread extends Thread {
@Override
public void run() {
// 线程执行的代码
}
}
public static void main(String[] args) {
MyThread t = new MyThread();
t.start();
}
采用继承Thread类方式
- 优点: 编写简单,如果需要访问当前线程,无需使用Thread.currentThread ()方法,直接使用this,即可获得当前线程
- 缺点:因为线程类已经继承了Thread类,所以不能再继承其他的父类
2、实现Runnable接口
如果一个类已经继承了其他类,就不能再继承Thread类,此时可以实现java.lang.Runnable接口。实现Runnable接口需要重写run()方法,然后将此Runnable对象作为参数传递给Thread类的构造器,创建Thread对象后调用其start()方法启动线程。
class MyRunnable implements Runnable {
@Override
public void run() {
// 线程执行的代码
}
}
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start();
}
采用实现Runnable接口方式:
- 优点:线程类只是实现了Runable接口,还可以继承其他的类。在这种方式下,可以多个线程共享同一个目标对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
- 缺点:编程稍微复杂,如果需要访问当前线程,必须使用Thread.currentThread()方法。
- 实现Callable接口与FutureTask
java.util.concurrent.Callable接口类似于Runnable,但Callable的call()方法可以有返回值并且可以抛出异常。要执行Callable任务,需将它包装进一个FutureTask,因为Thread类的构造器只接受Runnable参数,而FutureTask实现了Runnable接口。
class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
// 线程执行的代码,这里返回一个整型结果
return 1;
}
}
public static void main(String[] args) {
MyCallable task = new MyCallable();
FutureTask<Integer> futureTask = new FutureTask<>(task);
Thread t = new Thread(futureTask);
t.start();
try {
Integer result = futureTask.get(); // 获取线程执行结果
System.out.println("Result: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
采用实现Callable接口方式:
- 优点:
call()方法可以返回执行结果,也可以抛出受检异常(这是 Runnable 不具备的能力);线程类只实现接口,还可以继承其他类,便于复用。 - 缺点:使用相对复杂,必须先将
Callable包装到FutureTask(或提交到线程池)中才能执行;通过Future.get()获取结果时会阻塞调用线程,直到任务完成或超时。
4、使用线程池(Executor框架)
从Java 5开始引入的java.util.concurrent.ExecutorService和相关类提供了线程池的支持,这是一种更高效的线程管理方式,避免了频繁创建和销毁线程的开销。可以通过Executors类的静态方法创建不同类型的线程池。
class Task implements Runnable {
@Override
public void run() {
// 线程执行的代码
}
}
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(10); // 创建固定大小的线程池
for (int i = 0; i < 100; i++) {
executor.submit(new Task()); // 提交任务到线程池执行
}
executor.shutdown(); // 关闭线程池
}
采用线程池方式:
- 缺点:程池增加了程序的复杂度,特别是当涉及线程池参数调整和故障排查时。错误的配置可能导致死锁、资源耗尽等问题,这些问题的诊断和修复可能较为复杂。
- 优点:线程池可以重用预先创建的线程,避免了线程创建和销毁的开销,显著提高了程序的性能。对于需要快速响应的并发请求,线程池可以迅速提供线程来处理任务,减少等待时间。并且,线程池能够有效控制运行的线程数量,防止因创建过多线程导致的系统资源耗尽(如内存溢出)。通过合理配置线程池大小,可以最大化CPU利用率和系统吞吐量。
# 线程的状态有哪些?
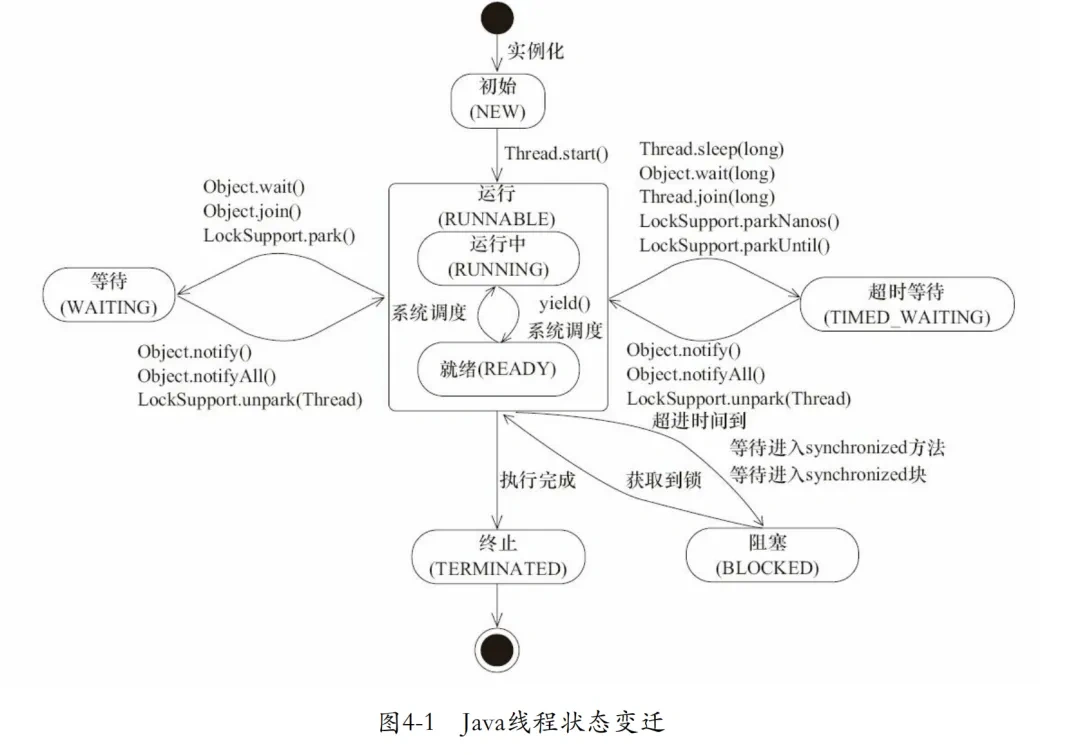
源自《Java并发编程艺术》 java.lang.Thread.State枚举类中定义了六种线程的状态,可以调用线程Thread中的getState()方法获取当前线程的状态。
| 线程状态 | 解释 |
|---|---|
| NEW | 尚未启动的线程状态,即线程创建,还未调用start方法 |
| RUNNABLE | 就绪状态(调用start,等待调度)+正在运行 |
| BLOCKED | 等待监视器锁时,陷入阻塞状态 |
| WAITING | 等待状态的线程正在等待另一线程执行特定的操作(如notify) |
| TIMED_WAITING | 具有指定等待时间的等待状态 |
| TERMINATED | 线程完成执行,终止状态 |
# 悲观锁和乐观锁的区别是什么?
- 乐观锁: 就像它的名字一样,对于并发间操作产生的线程安全问题持乐观状态,乐观锁认为竞争不总 是会发生,因此它不需要持有锁,将比较-替换这两个动作作为一个原子操作尝试去修改内存中的变量,如果失败则表示发生冲突,那么就应该有相应的重试逻辑。
- 悲观锁: 还是像它的名字一样,对于并发间操作产生的线程安全问题持悲观状态,悲观锁认为竞争总 是会发生,因此每次对某资源进行操作时,都会持有一个独占的锁,就像 synchronized,不管三七二十一,直接上了锁就操作资源了。
# MySQL中的事务隔离级别有哪些?
- 读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到;
- 读提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到;
- 可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
- 串行化(serializable);会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
按隔离水平高低排序如下:

针对不同的隔离级别,并发事务时可能发生的现象也会不同。
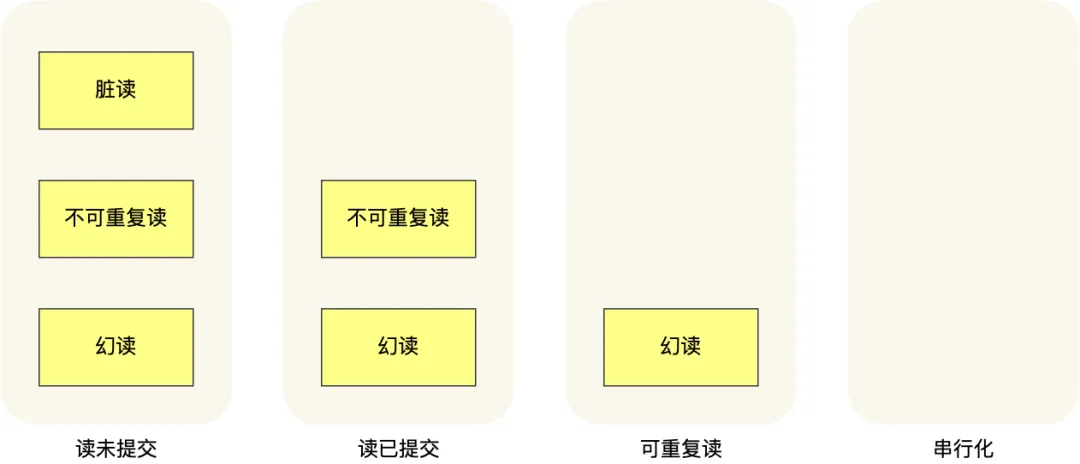
也就是说:
- 在「读未提交」隔离级别下,可能发生脏读、不可重复读和幻读现象;
- 在「读提交」隔离级别下,可能发生不可重复读和幻读现象,但是不可能发生脏读现象;
- 在「可重复读」隔离级别下,可能发生幻读现象,但是不可能脏读和不可重复读现象;
- 在「串行化」隔离级别下,脏读、不可重复读和幻读现象都不可能会发生。
接下来,举个具体的例子来说明这四种隔离级别,有一张账户余额表,里面有一条账户余额为 100 万的记录。然后有两个并发的事务,事务 A 只负责查询余额,事务 B 则会将我的余额改成 200 万,下面是按照时间顺序执行两个事务的行为:
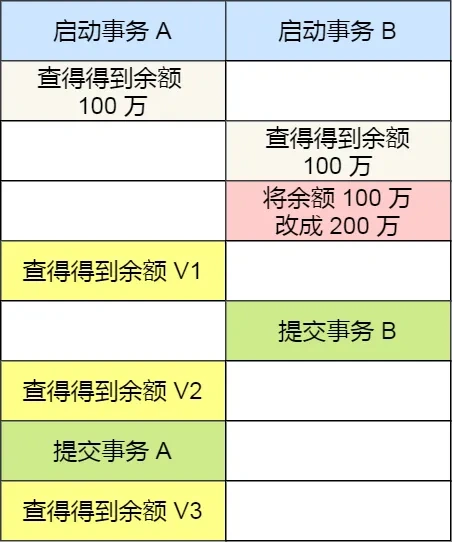
在不同隔离级别下,事务 A 执行过程中查询到的余额可能会不同:
- 在「读未提交」隔离级别下,事务 B 修改余额后,虽然没有提交事务,但是此时的余额已经可以被事务 A 看见了,于是事务 A 中余额 V1 查询的值是 200 万,余额 V2、V3 自然也是 200 万了;
- 在「读提交」隔离级别下,事务 B 修改余额后,因为没有提交事务,所以事务 A 中余额 V1 的值还是 100 万,等事务 B 提交完后,最新的余额数据才能被事务 A 看见,因此额 V2、V3 都是 200 万;
- 在「可重复读」隔离级别下,事务 A 只能看见启动事务时的数据,所以余额 V1、余额 V2 的值都是 100 万,当事务 A 提交事务后,就能看见最新的余额数据了,所以余额 V3 的值是 200 万;
- 在「串行化」隔离级别下,事务 B 在执行将余额 100 万修改为 200 万时,由于此前事务 A 执行了读操作,这样就发生了读写冲突,于是就会被锁住,直到事务 A 提交后,事务 B 才可以继续执行,所以从 A 的角度看,余额 V1、V2 的值是 100 万,余额 V3 的值是 200万。
这四种隔离级别具体是如何实现的呢?
- 对于「读未提交」隔离级别的事务来说,因为可以读到未提交事务修改的数据,所以直接读取最新的数据就好了;
- 对于「串行化」隔离级别的事务来说,通过加读写锁的方式来避免并行访问;
- 对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 Read View来实现的,它们的区别在于创建 Read View 的时机不同,「读提交」隔离级别是在「每个语句执行前」都会重新生成一个 Read View,而「可重复读」隔离级别是「启动事务时」生成一个 Read View,然后整个事务期间都在用这个 Read View。
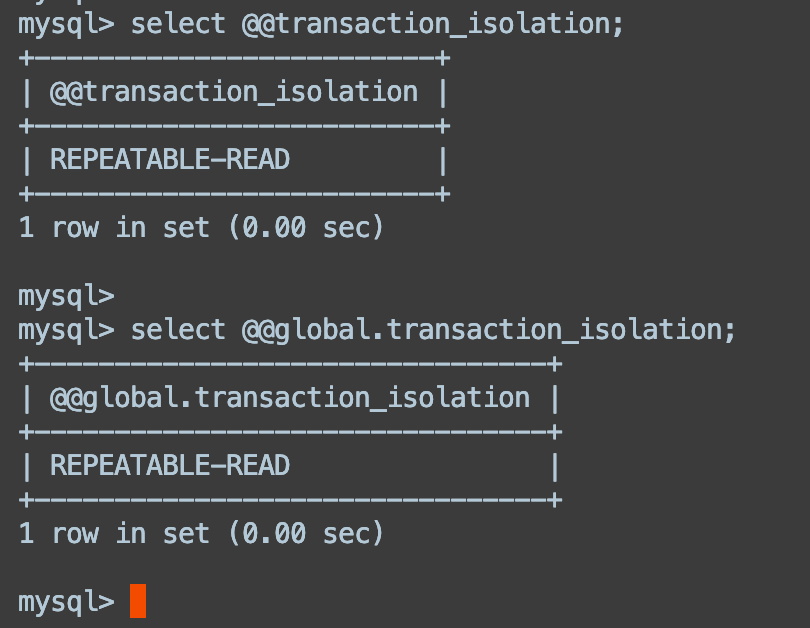
# 查询当前数据库的事务隔离级别的命令是什么?
在 MySQL8.0+ 版本中:
- 查看当前会话隔离级别:
select @@transaction_isolation; - 查看系统当前隔离级别:
select @@global.transaction_isolation;
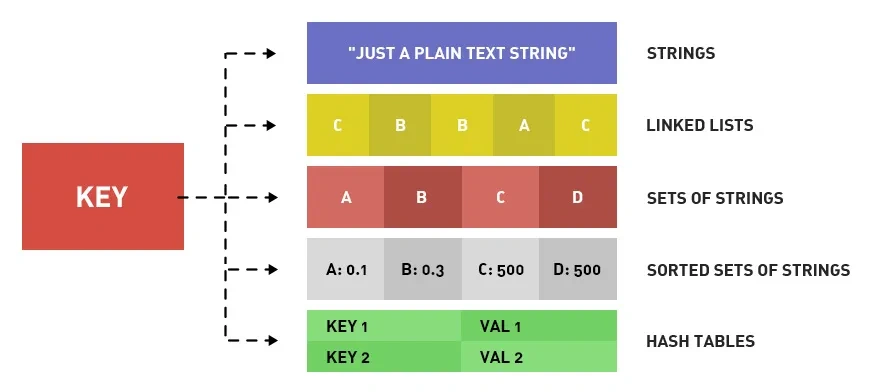
# redis的常见数据结构有哪些?
Redis 提供了丰富的数据类型,常见的有五种数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
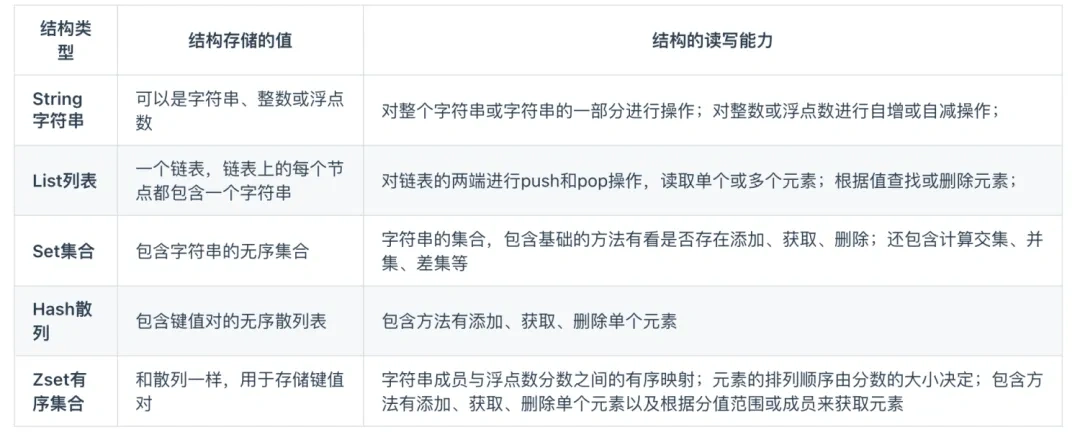
随着 Redis 版本的更新,后面又支持了四种数据类型:BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增)。Redis 五种数据类型的应用场景:
- String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
- List 类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
- Hash 类型:缓存对象、购物车等。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
- Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
- BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
- GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
# spring的AOP的作用是什么?
Spring AOP 目的是对于面向对象思维的一种补充,而不是像引入命令式、函数式编程思维让他顺应另一种开发场景。在我个人的理解下AOP更像是一种对于不支持多继承的弥补,除开对象的主要特征(我更喜欢叫“强共性”)被抽象为了一条继承链路,对于一些“弱共性”,AOP可以统一对他们进行抽象和集中处理。
举一个简单的例子,打印日志。需要打印日志可能是许多对象的一个共性,这在企业级开发中十分常见,但是日志的打印并不反应这个对象的主要共性。而日志的打印又是一个具体的内容,它并不抽象,所以它的工作也不可以用接口来完成。而如果利用继承,打印日志的工作又横跨继承树下面的多个同级子节点,强行侵入到继承树内进行归纳会干扰这些强共性的区分。
这时候,我们就需要AOP了。AOP首先在一个Aspect(切面)里定义了一些Advice(增强),其中包含具体实现的代码,同时整理了切入点,切入点的粒度是方法。最后,我们将这些Advice织入到对象的方法上,形成了最后执行方法时面对的完整方法。
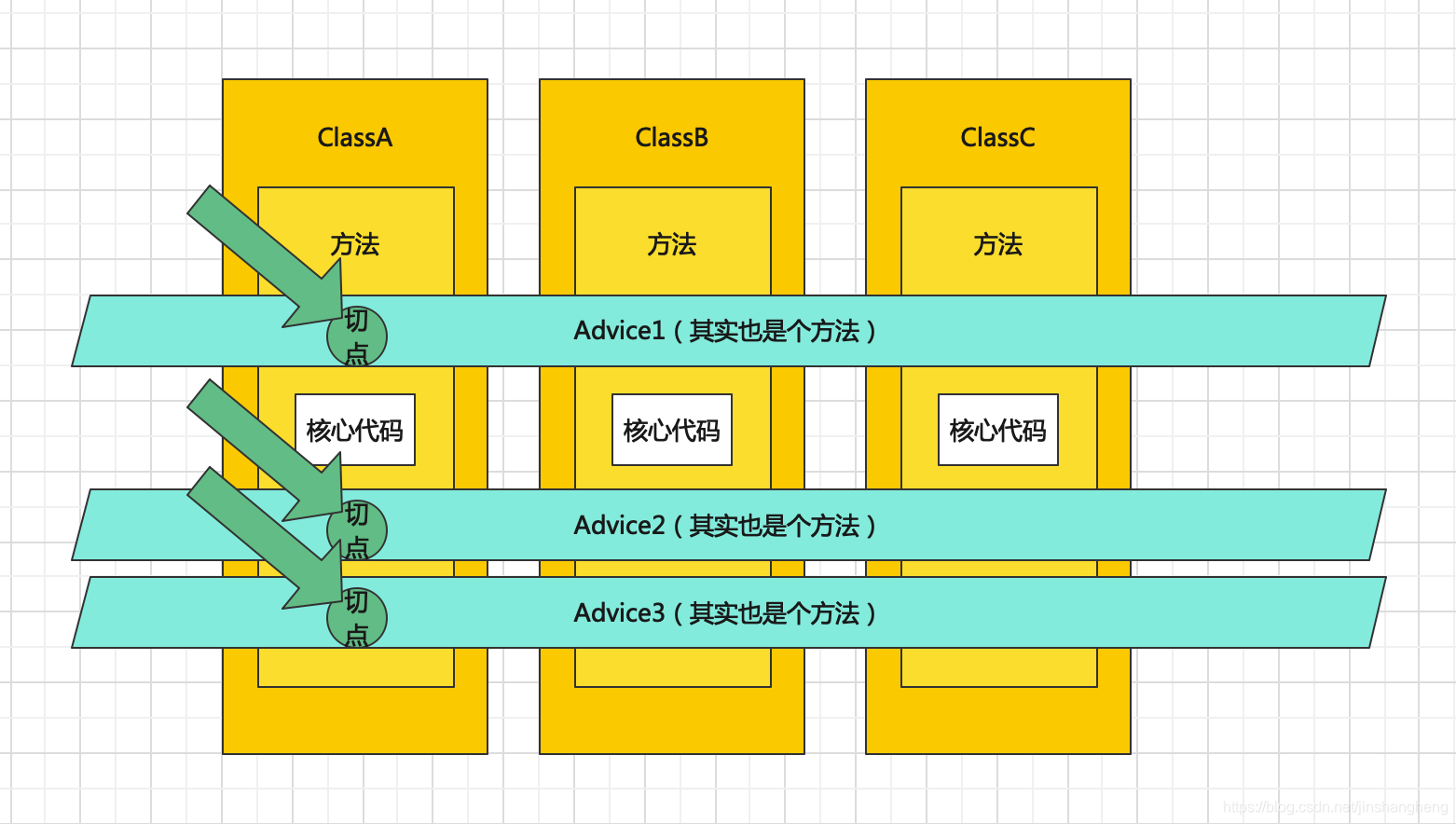
# AOP 常见的通知类型有哪些?相关术语解释
在 Spring AOP 中,通知(Advice)是切面在特定连接点(Join Point)采取的行动,常见的通知类型有以下三种,有“around”,“before”和“after”三种类型。在很多的 AOP 实现框架中,Advice 通常作为一个拦截器,也可以包含许多个拦截器作为一条链路围绕着 Join point 进行处理。
- 前置通知(Before Advice):在目标方法执行之前调用通知。它可以用于执行一些前置的操作,例如参数检查、权限验证等。比如下面的代码使用了
@Before注解,该注解的参数是一个切点表达式,表示在com.example.service.MyService类中的任何方法执行之前,都会执行beforeAdvice方法。
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
@Aspect
public class MyAspect {
@Before("execution(* com.example.service.MyService.*(..))")
public void beforeAdvice() {
System.out.println("This is before advice. Executing before the target method.");
}
}
- 后置通知(After Advice):在目标方法执行完成之后调用通知,无论目标方法是否正常结束或抛出异常。后置通知通常用于释放资源或执行一些清理工作。比如下面的代码,这里使用了
@After注解,意味着afterAdvice方法会在com.example.service.MyService类中的任何方法执行之后被调用。
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.After;
@Aspect
public class MyAspect {
@After("execution(* com.example.service.MyService.*(..))")
public void afterAdvice() {
System.out.println("This is after advice. Executing after the target method.");
}
}
- 环绕通知(Around Advice):环绕通知是最强大的一种通知,它可以在目标方法调用前后自定义操作,并且可以控制目标方法是否执行,以及修改其返回值。环绕通知可以实现更复杂的逻辑,如事务管理。比如下面的代码,
@Around注解表明这是一个环绕通知,ProceedingJoinPoint参数表示正在执行的连接点,可以调用proceed()方法来执行目标方法。环绕通知需要手动调用proceed()方法,否则目标方法不会被执行,同时可以对返回值进行修改。
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
@Aspect
public class MyAspect {
@Around("execution(* com.example.service.MyService.*(..))")
public Object aroundAdvice(ProceedingJoinPoint pjp) throws Throwable {
System.out.println("This is around advice. Before target method.");
Object result = pjp.proceed(); // 执行目标方法
System.out.println("This is around advice. After target method.");
return result;
}
}
# linux命令行如何找到占用端口的进程PID
可以通过 lsof 命令来找到占用端口的进程 ID,例如要查找占用 TCP 端口 3306 的进程 PID,可以执行以下命令:
lsof -i :3306 -sTCP:LISTEN

上述命令中,-i参数用于指定要监听的网络地址和端口号,:后面跟上端口号;-sTCP:LISTEN表示只列出状态为监听(LISTEN)的 TCP 连接,这样可以更精准地找到占用指定端口的进程。执行该命令后,如果有进程占用 3306 端口,会显示相关进程信息,其中PID列即为进程的 PID 号。
也可以通过 netstat 命令来找到占用端口的进程 ID,例如要查找占用 TCP 端口 3306 的进程 PID,可以执行以下命令:
netstat -tulnpe | grep :3306

上述命令中,-t表示列出 TCP 连接,-u表示列出 UDP 连接,-l表示只列出处于监听状态的连接,-n表示以数字形式显示地址和端口号,避免进行 DNS 解析,从而加快命令执行速度,-p表示显示占用该连接的进程 ID 和进程名称,-e表示显示扩展信息。管道符|将netstat命令的输出作为grep命令的输入,grep :3306用于在netstat命令的输出结果中查找包含:8080的行,即找到占用 3306 端口的进程相关信息,其中包含进程的 PID 号。
# 其他
- 个人未来职业规划
- 未来有无考研考公的打算?
对了,最新的互联网大厂后端面经都会在公众号首发,别忘记关注哦!!如果你想加入百人技术交流群,扫码下方二维码回复「加群」。
