# 上海银行 Java 面试

大家好,我是小林。
最近后台好多读者发私信问我,现在有哪些银行已经开始秋招了。
现在到 9 月份了,我目前看到不少银行都开秋招了,像北京银行、广州农商银行、上海银行、招商银行、平安银行、华润银行这些,都已经开始招人了。
而且我列出来的这些银行,都有信息科技岗, 也就是银行里的软件开发岗。
虽然说银行做开发,大多时候用的是 Java,但也不是说你不会 Java 就不能投,想投还是可以投的。
就拿上海银行举例,我看了他们应用开发岗的秋招要求,只要你会一门开发语言,再懂一种数据库,就能投递这个岗位了。
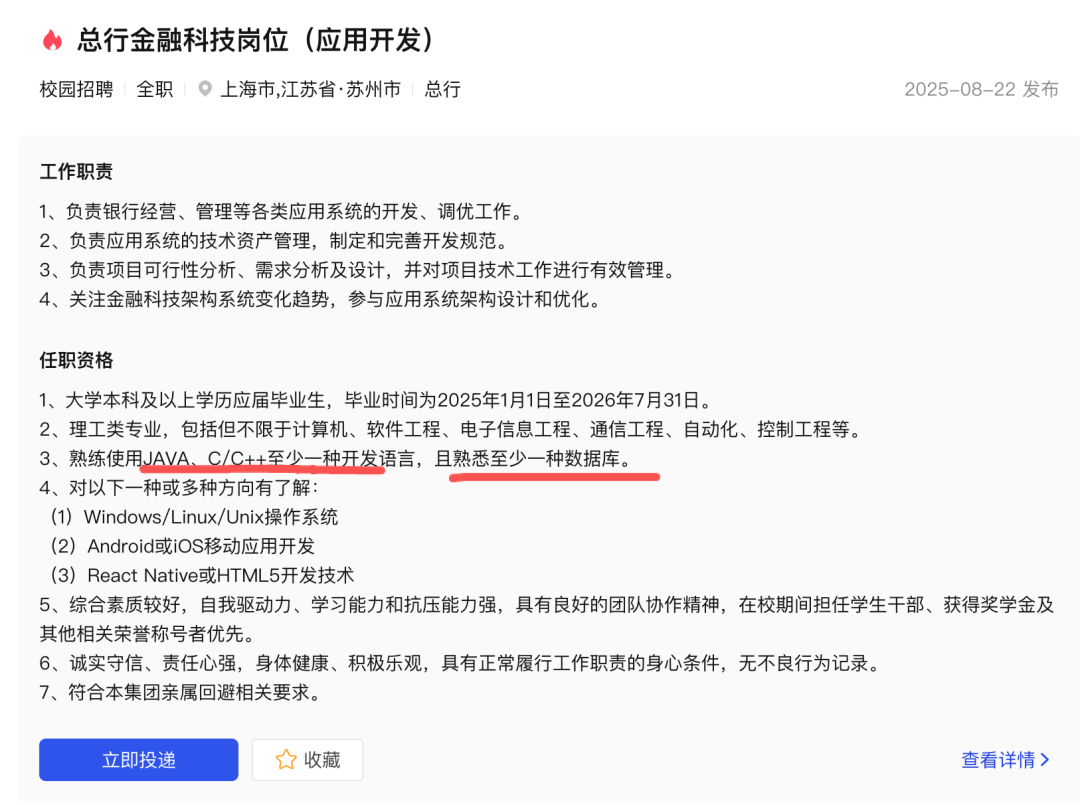
上海银行线下线上面试都有,最近有看到有同学已经被上海银行约线下面试了

另外我也翻了前两年咱们训练营记录的校招情况,发现大部分银行差不多从 9 月 20 多号开始,就会陆续通知面试了 ,现在刚好就到这个时间点了。
上海银行金融科技岗校招,第一年月薪大多是 16k,要是加上年终奖,一年到手大概 20 万多一点。工作地点主要在上海,要么就是苏州。
我看了网上大家说的薪资情况,对这块的评价不怎么好。
主要是薪资体系有点绕,而且第二年的薪资会变,具体看你工作表现:要是干得不好,第二年薪资可能还没第一年高;要是干得好,年终奖就能多拿点。
说实话,这个薪资确实不算高,但上海银行是国企,优势就在于稳定。平时基本 6 点就能下班,不过要是赶上大项目赶进度,加班肯定是免不了的。
要论技术上的成长,银行肯定比不上互联网公司。
如果想在技术上多学东西、有发展,其实更建议刚毕业去互联网公司。虽然互联网公司变化快、不稳定,但你在那儿积累了工作经验后,再跳槽去国企安稳待着也没问题。
当然,不是所有人都想在技术上往上走。要是就想工作轻松点、稳定点,还是有不少同学会选国企。这事儿没什么对不对的,就看你自己更看重什么了。
话说回来,上海银行的面试难不难呢?我整体感觉不算难。一场技术面试大概就 20 到 30 分钟,问的技术八股题也就 5 到 10 个左右。
就拿一份上海银行 Java 岗一面的面经来说吧,除了问项目相关的问题,就只问了 5 道技术题。
内容主要围绕 Java、MySQL、Redis 和 Linux 命令,刚好和招聘要求里写的一致,像网络、操作系统这些知识点,一道都没问。

# 上海银行(Java 一面 20 分钟)
# 1. mysql 中mvcc 原理是什么?用了什么数据结构?
MVCC允许多个事务同时读取同一行数据,而不会彼此阻塞,每个事务看到的数据版本是该事务开始时的数据版本。这意味着,如果其他事务在此期间修改了数据,正在运行的事务仍然看到的是它开始时的数据状态,从而实现了非阻塞读操作。
对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 Read View 来实现的,它们的区别在于创建 Read View 的时机不同,大家可以把 Read View 理解成一个数据快照,就像相机拍照那样,定格某一时刻的风景。
- 「读提交」隔离级别是在「每个select语句执行前」都会重新生成一个 Read View,因此可能看到其他事务提交的新数据(不可重复读)。
- 「可重复读」隔离级别是执行第一条select时,生成一个 Read View,然后整个事务期间都在用这个 Read View,因此能保证可重复读(避免不可重复读)。
MVCC 的实现依赖以下关键数据结构:
- 版本链:由行记录的 DB_ROLL_PTR 串联形成的链表,每个节点是数据的一个历史版本(存储在 undo log 中)。
- Read View:本质是一个包含活跃事务 ID 信息的结构体,用于判断版本可见性。
- Undo Log:存储旧版本数据的日志文件
- 事务 ID 生成器:InnoDB 维护一个全局自增的事务 ID 计数器,确保每个事务的 ID 唯一且递增。
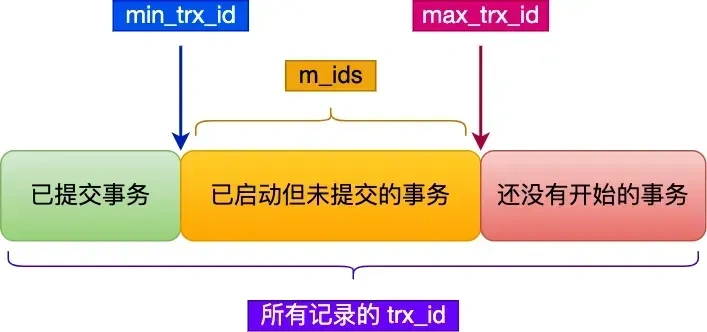
先来看看 Read View 有四个重要的字段:
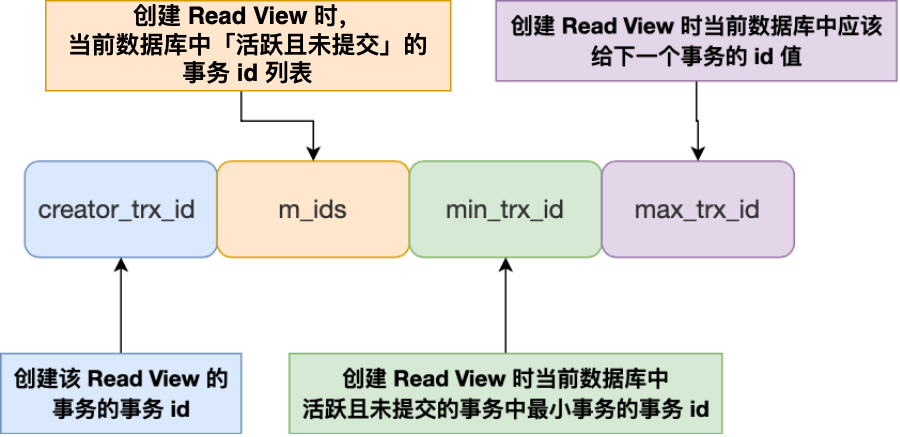
- m_ids :指的是在创建 Read View 时,当前数据库中「活跃事务」的事务 id 列表,注意是一个列表,“活跃事务”指的就是,启动了但还没提交的事务。
- min_trx_id :指的是在创建 Read View 时,当前数据库中「活跃事务」中事务 id 最小的事务,也就是 m_ids 的最小值。
- max_trx_id :这个并不是 m_ids 的最大值,而是创建 Read View 时当前数据库中应该给下一个事务的 id 值,也就是全局事务中最大的事务 id 值 + 1;
- creator_trx_id :指的是创建该 Read View 的事务的事务 id。
对于使用 InnoDB 存储引擎的数据库表,它的聚簇索引记录中都包含下面两个隐藏列:
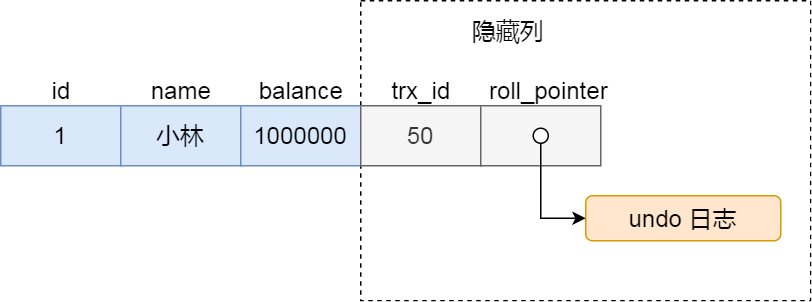
- trx_id,当一个事务对某条聚簇索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;
- roll_pointer,每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
在创建 Read View 后,我们可以将记录中的 trx_id 划分这三种情况:
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
- 如果记录的 trx_id 值小于 Read View 中的 min_trx_id 值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。
- 如果记录的 trx_id 值大于等于 Read View 中的 max_trx_id 值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id 之间,需要判断 trx_id 是否在 m_ids 列表中:
- 如果记录的 trx_id 在 m_ids 列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 不在 m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
# 2. synchronized实现原理是什么?用了什么数据结构
synchronized是Java提供的原子性内置锁,这种内置的并且使用者看不到的锁也被称为监视器锁,
使用synchronized之后,会在编译之后在同步的代码块前后加上monitorenter和monitorexit字节码指令,他依赖操作系统底层互斥锁实现。他的作用主要就是实现原子性操作和解决共享变量的内存可见性问题。
执行monitorenter指令时会尝试获取对象锁,如果对象没有被锁定或者已经获得了锁,锁的计数器+1。此时其他竞争锁的线程则会进入等待队列中。执行monitorexit指令时则会把计数器-1,当计数器值为0时,则锁释放,处于等待队列中的线程再继续竞争锁。
synchronized是排它锁,当一个线程获得锁之后,其他线程必须等待该线程释放锁后才能获得锁,而且由于Java中的线程和操作系统原生线程是一一对应的,线程被阻塞或者唤醒时时会从用户态切换到内核态,这种转换非常消耗性能。
从内存语义来说,加锁的过程会清除工作内存中的共享变量,再从主内存读取,而释放锁的过程则是将工作内存中的共享变量写回主内存。
实际上大部分时候我认为说到monitorenter就行了,但是为了更清楚的描述,还是再具体一点。
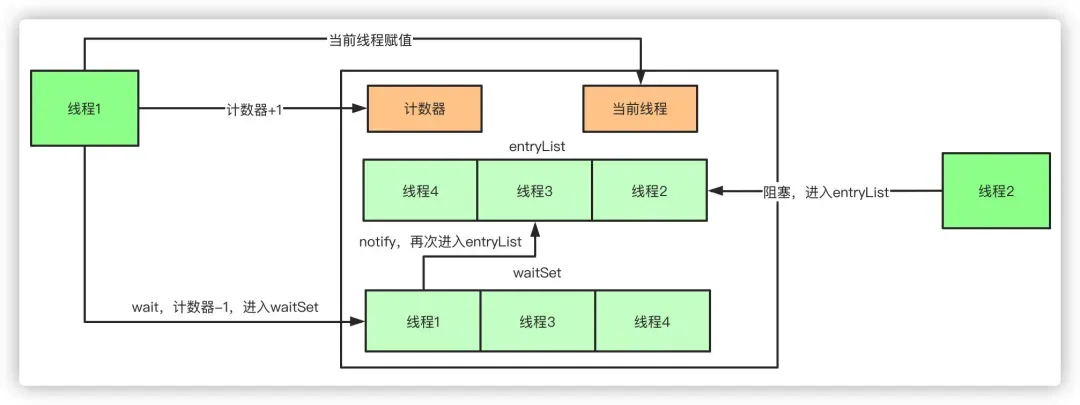
如果再深入到源码来说,synchronized实际上有两个队列waitSet和entryList。
当多个线程进入同步代码块时,首先进入entryList
有一个线程获取到monitor锁后,就赋值给当前线程,并且计数器+1
如果线程调用wait方法,将释放锁,当前线程置为null,计数器-1,同时进入waitSet等待被唤醒,调用notify或者notifyAll之后又会进入entryList竞争锁
如果线程执行完毕,同样释放锁,计数器-1,当前线程置为null
# 3. 两个线程交替打印1-10 如何实现?
利用synchronized加锁,结合wait()和notify()实现线程间通信:
public class AlternatePrint {
privatestaticint count = 1;
privatestaticfinal Object lock = new Object();
public static void main(String[] args) {
// 线程1:打印奇数
Thread thread1 = new Thread(() -> {
while (count <= 10) {
synchronized (lock) {
// 确保当前是奇数才打印
if (count % 2 == 1) {
System.out.println(Thread.currentThread().getName() + ": " + count);
count++;
lock.notify(); // 唤醒另一个线程
} else {
try {
lock.wait(); // 等待,释放锁
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}, "线程A");
// 线程2:打印偶数
Thread thread2 = new Thread(() -> {
while (count <= 10) {
synchronized (lock) {
// 确保当前是偶数才打印
if (count % 2 == 0) {
System.out.println(Thread.currentThread().getName() + ": " + count);
count++;
lock.notify(); // 唤醒另一个线程
} else {
try {
lock.wait(); // 等待,释放锁
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}, "线程B");
thread1.start();
thread2.start();
}
}
运行上述代码,都会输出类似以下结果:
线程A: 1
线程B: 2
线程A: 3
线程B: 4
线程A: 5
线程B: 6
线程A: 7
线程B: 8
线程A: 9
线程B: 10
# 4. 你项目中redis数据一致性问题怎么解决的?
对于读数据,我会选择旁路缓存策略,如果 cache 不命中,会从 db 加载数据到 cache。对于写数据,我会选择更新 db 后,再删除缓存。
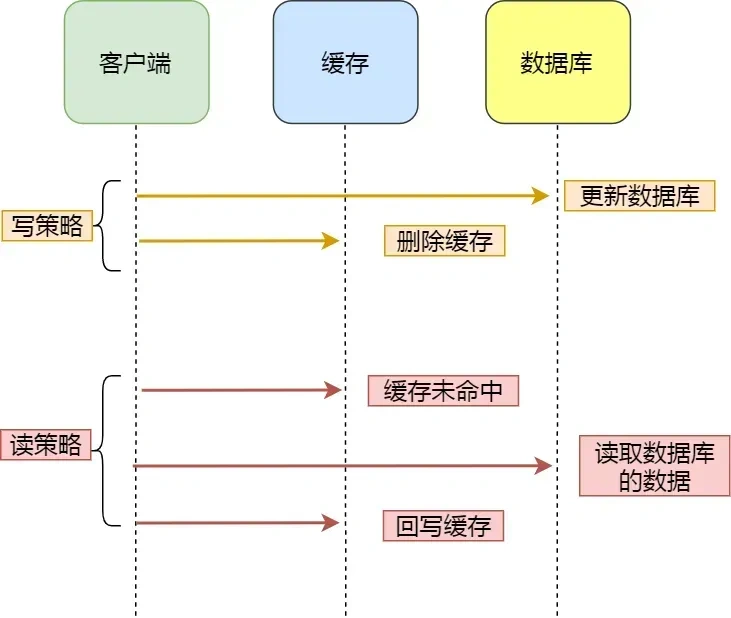
缓存是通过牺牲强一致性来提高性能的。这是由CAP理论决定的。缓存系统适用的场景就是非强一致性的场景,它属于CAP中的AP。所以,如果需要数据库和缓存数据保持强一致,就不适合使用缓存。
所以使用缓存提升性能,就是会有数据更新的延迟。这需要我们在设计时结合业务仔细思考是否适合用缓存。然后缓存一定要设置过期时间,这个时间太短、或者太长都不好:
- 太短的话请求可能会比较多的落到数据库上,这也意味着失去了缓存的优势。
- 太长的话缓存中的脏数据会使系统长时间处于一个延迟的状态,而且系统中长时间没有人访问的数据一直存在内存中不过期,浪费内存。
但是,通过一些方案优化处理,是可以最终一致性的。
针对删除缓存异常的情况,可以使用 2 个方案避免:
- 删除缓存重试策略(消息队列)
- 订阅 binlog,再删除缓存(Canal+消息队列)
消息队列方案
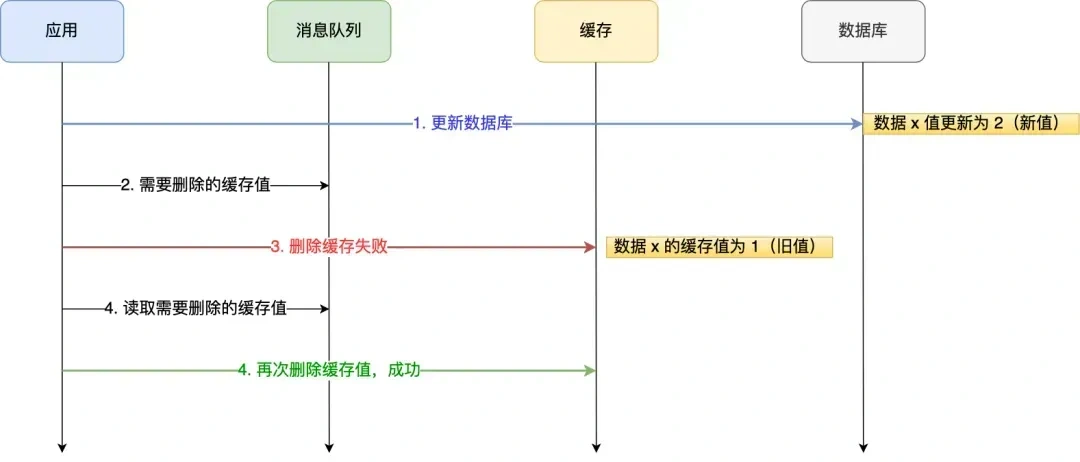
我们可以引入消息队列,将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。
- 如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
- 如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
举个例子,来说明重试机制的过程。
重试删除缓存机制还可以,就是会造成好多业务代码入侵。
订阅 MySQL binlog,再操作缓存
「先更新数据库,再删缓存」的策略的第一步是更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在 binlog 里。
于是我们就可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再执行缓存删除,阿里巴巴开源的 Canal 中间件就是基于这个实现的。
Canal 模拟 MySQL 主从复制的交互协议,把自己伪装成一个 MySQL 的从节点,向 MySQL 主节点发送 dump 请求,MySQL 收到请求后,就会开始推送 Binlog 给 Canal,Canal 解析 Binlog 字节流之后,转换为便于读取的结构化数据,供下游程序订阅使用。
下图是 Canal 的工作原理:
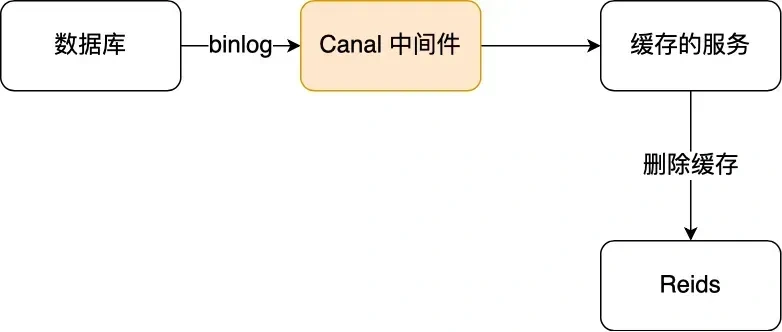
将binlog日志采集发送到MQ队列里面,然后编写一个简单的缓存删除消息者订阅binlog日志,根据更新log删除缓存,并且通过ACK机制确认处理这条更新log,保证数据缓存一致性。
# 5. linux如何查看一个java进程?
ps 是进程查看的基础命令,结合参数可专门筛选 Java 进程:
# 查看所有 Java 进程(最常用)
ps -ef | grep java
# 简化输出(只显示进程 ID、命令等关键信息)
ps -aux | grep java
ps -ef:显示系统中所有进程的详细信息(UID、PID、PPID、启动时间等)grep java:过滤出包含 "java" 关键字的进程(即 Java 进程)- 输出中,
PID列是进程 ID,COMMAND列会显示 Java 程序的启动命令(如java -jar app.jar)
也可以用jps,它是 JDK 自带的命令,专门用于查看 Java 进程,简洁高效:
# 基本用法:显示所有 Java 进程的 PID 和主类名/JAR 包名
jps
# 显示详细信息(包括启动参数)
jps -lvm
# 6. 其他
- 项目最难的技术是什么?你是怎么解决的?
- 学校课程有没有接触过大数据相关的,你学到了哪些思想?
- 反问,面试官说基础不太行,到这已经听出来凉了。。。
对了,最新的互联网大厂后端面经都会在公众号首发,别忘记关注哦!!如果你想加入百人技术交流群,扫码下方二维码回复「加群」。
